2024工作周期安排
2024项目整体规划
沐曦测试(已完成)
沐曦性能测试研究
沐曦Benchmark相关测试
沐曦模型适配表
2024-02-26沐曦沟通报告
智能打标
数据打标服务Json样例
智能打标寒武纪大模型思路
业务层优先级排序
智能打标流程图
打标API接口文档
图像内容识别
其他
申报项目文本段落
研发链相关资料文档
国产GPU虚拟化培训介绍
大模型比赛
相关资料
智能填单_填单 启动命令
2024私人规划
ChatGPT API账号记录
公众号相关资料
基于 Docker 的深度学习环境:入门篇
ollama
Ollama
ReFT
ReFT AI论文笔记
ReFT概要
分布式对齐搜索 DAS
不是每个人都开始使用 ReFT 吗?
ReFT 微调Llama3
ReFT 算法详解
-
+
首页
ReFT概要
# ReFT是每个人都需要的么? # 抽象: > 大型神经模型旨在通过使用参数高效微调 (PEFT) 技术更新到有限数量的权重来进行调整。然而,编辑表示可能是一个更有效的选择,因为之前的大量可解释性研究表明,表示编码重要的语义信息。 > > 为了验证这一理论,我们创建了一系列 ReFT 技术。ReFT 技术使用冻结的基础模型学习对隐藏表示的特定任务干预。 > > 我们定义了低秩线性子空间 ReFT (LoReFT),这是 ReFT 系列的一个强大实例,我们发现了这种技术的消融,它以牺牲性能为代价来提高效率。两者都学习的干预措施的参数效率比 LoRA 高 15 倍到 65 倍,并且可以用作当前 PEFT 的直接替代品。 > > 我们演示了 LoReFT 的四个算术推理问题、指令调整、GLUE 和八个常识性推理任务。我们的 ReFT 始终优于最先进的 PEFT,并在所有这些研究中提供最佳的效率/性能比。 > > 通用的 ReFT 培训库在 [此 https URL] (https://github.com/stanfordnlp/pyreft) 上向公众提供。 # 摘要注释 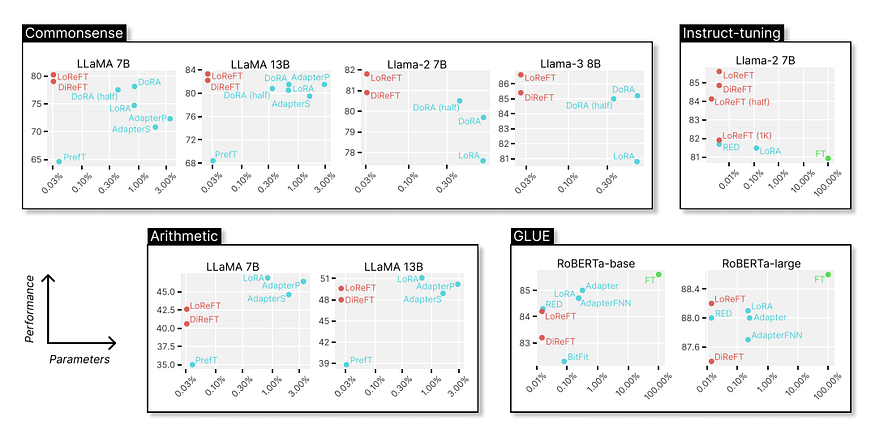 图:在四个基准上应用于 LLaMA、Llama-2、Llama-3 和 RoBERTa 模型的 LoReFT 和各种 PEFT 的性能参数计数。在所有任务中,LoReFT 都能提供相当甚至最先进的性能,尽管训练的参数比现有的 PEFT 少得多。在我们的评估中,它的价值对于最大的模型来说尤其明显。 请注意,FT 不是 PEFT 或 ReFT 方法;相反,它是全参数微调。 语言模型正在成为快速变化的人工智能领域中广泛应用的重要工具。尽管如此,一个关键问题仍然是难以有效地为特定应用程序定制这些大型模型。 使用传统方法需要完全微调,这需要花费大量时间和资源。呈现表示微调 (ReFT),一种专注于模型表示而不是其权重的新方法,提供了一种更有效的替代品。 我们将在这篇博文中探讨 ReFT 的新方法和令人鼓舞的结果,尤其是其旗舰应用程序低秩线性子空间 ReFT (LoReFT)。 # ReFT 概述 ReFT 方法基于这样一种认识,即语言模型隐藏的表示本质上编码了丰富的语义信息。 这意味着我们可以通过直接干预这些表示来成功控制模型行为,而无需改变模型权重。 这种想法不同于传统的参数高效微调 (PEFT) 技术,后者专注于改变模型权重的有限子集。 LoReFT 和其他 ReFT 技术使用冻结基模型。它们通过学习对隐藏表示的任务特定处理,为当前的 PEFT 提供了一种有效的替代品。 主要思想是,当编辑表示而不是权重时,可以进行更复杂和有效的模型调整。 # 方法:ReFT 的运营 ReFT 使用低秩线性子空间干预。LoReFT 特别影响低秩投影矩阵定义的线性子空间中的隐藏表示。 分布式对齐搜索 (DAS) 技术已被证明可以成功定位模型表示中的概念,为该方法提供了基础。 ReFT 方法细分如下: - **Low-Rank Projection (低秩投影):**主要概念是通过低秩投影矩阵在模型的表示空间内定义一个子空间。然后,该子空间用于干预。 - **特定任务干预:**ReFT 可以通过弄清楚需要更改哪些特定表示以获得所需的结果来指导模型在推理过程中的行为。 - **参数效率:**LoReFT 在许多作业中实现了最先进的性能,其参数比 LoRA 等经典 PEFT 方法少 65 倍。这使得 LoReFT 非常高效。 # 主要发现和结果 ReFT,尤其是 LoReFT,已被证明在多个基准测试中有效,这表明它们可以成为当前微调技术的有力替代品。亮点如下: - **常识推理:**LoReFT 在精度和参数效率方面优于所有其他技术,实现了最先进的性能。 - **指令遵循:**LoReFT 在指令调优测试中的性能优于完整参数微调和其他 PEFT 算法,展示了其处理复杂、长格式文本创建的能力。 - **算术推理:**尽管 LoReFT 表现出有竞争力的性能,但它也清楚地表明,需要更多的研究才能充分实现 LoReFT 在越来越具有挑战性的推理任务中的潜力。 - **自然语言理解:**LoReFT 表现出对各种模型大小和任务的适应性,这从它在 GLUE 基准测试中的表现可以看出,这与最有效的 PEFT 方法相当。 # 应用和影响 ReFT 具有重大影响,并为模型微调提供了全新的视角: - **资源效率:**ReFT 通过显著减少需要更新的参数数量,最大限度地减少了与微调大型模型相关的计算和内存成本。 - **可扩展性:**随着模型规模的不断扩大,像 ReFT 这样提供可扩展微调解决方案的技术将变得越来越重要。 - **多面性:** ReFT 是在各种应用程序中部署模型的理想选择,因为它能够在各种作业中有效执行,因此无需大量重新训练。 此外,ReFT 架构对于在资源有限的情况下(如边缘计算平台或移动设备)部署 AI 系统具有实际意义。这不仅仅是一项学术努力。 # 最后的思考 ReFT 及其分支 LoReFT 是模型微调领域的一个值得注意的发展。通过表示编辑而不是权重调整,ReFT 提供了一种更有效、可扩展和灵活的模型适应方法。 随着 AI 继续渗透到技术和社会的方方面面,像 ReFT 这样的创新对于确保这些系统能够得到有效和高效的部署至关重要。 这不是旅程的终点。为了实现更好的经济和能力,未来的研究将检查 ReFT 在其他模型系列中的应用,进一步探究其背后的因果机制,并改进方法。 ReFT 有力地提醒我们,在人工智能 (AI) 领域,每个参数都很重要,有时,少即是多。
yg9538
2024年12月9日 16:17
1473
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期