2024工作周期安排
2024项目整体规划
沐曦测试(已完成)
沐曦性能测试研究
沐曦Benchmark相关测试
沐曦模型适配表
2024-02-26沐曦沟通报告
智能打标
数据打标服务Json样例
智能打标寒武纪大模型思路
业务层优先级排序
智能打标流程图
打标API接口文档
图像内容识别
其他
申报项目文本段落
研发链相关资料文档
国产GPU虚拟化培训介绍
大模型比赛
相关资料
智能填单_填单 启动命令
2024私人规划
ChatGPT API账号记录
公众号相关资料
基于 Docker 的深度学习环境:入门篇
ollama
Ollama
ReFT
ReFT AI论文笔记
ReFT概要
分布式对齐搜索 DAS
不是每个人都开始使用 ReFT 吗?
ReFT 微调Llama3
ReFT 算法详解
-
+
首页
ReFT 算法详解
 # 使用 ReFT 有什么优势? ## ReFT 的主要优势之一是其参数效率。 传统的微调方法需要更新模型参数的很大一部分,这可能计算成本高昂且耗费大量资源,尤其是对于具有数十亿个参数的大型语言模型。**ReFT 方法通常需要少几个数量级的参数训练,从而缩短训练时间并降低内存要求。** # ReFT 与 PeFT 有何不同? > 力量在于差异,而不是相似之处! ## ReFT (表示微调) 在几个关键方面与传统的参数高效微调 (PEFT) 方法不同: ## 1.干预对象 主要区别在于干预或适应过程的目标。PEFT 方法,例如适配器(例如 LoRA、DoRA)和前缀调整,侧重于修改模型的权重或引入额外的权重矩阵。相比之下,**ReFT 方法不会直接修改模型的权重;相反,它们会干预模型在前向传递期间计算的隐藏表示。** ## 2. 适应机制 PEFT 方法(如 LoRA 和 DoRA)学习模型权重矩阵的权重更新或低秩近似值。然后,在推理期间,这些权重更新将合并到基础模型的权重中,从而不会产生额外的计算开销。相反,**ReFT 方法学习在推理过程中操纵模型在特定层和位置的表示的干预。这种干预过程会产生一些计算开销,但可以实现更有效的适应。** ## 3. 灵感和动机 **PEFT 方法的主要动机是需要参数高效的适应,从而降低微调大型语言模型的计算成本和内存要求**。另一方面,**ReFT 方法受到语言模型可解释性最新工作的启发,该工作表明,丰富的语义信息被编码在这些模型学习的表示中。R**eFT 旨在利用和利用这些编码知识来实现更高效和有效的模型适应。 ## 4. 参数效率 PEFT 和 ReFT 方法都设计为参数效率高,但 ReFT 方法在实践中证明了更高的参数效率。**例如,LoReFT(低秩线性子空间 ReFT)方法通常需要训练的参数比 LoRA 等最先进的 PEFT 方法少 10-50 倍**,同时在各种 NLP 基准测试中实现有竞争力或卓越的性能。 ## 5. 可解释性和可解释性 **虽然 PEFT 方法主要侧重于有效适应,但 ReFT 方法在可解释性和可解释性方面提供了额外的优势。** 通过干预已知对特定语义信息进行编码的表示,**ReFT 方法可以深入了解语言模型如何处理和理解语言,从而有可能实现更透明和值得信赖的 AI 系统。** 让我们更深入地研究一下。 # ReFT 模型架构 ReFT 模型架构定义了**干预**的一般概念,这基本上意味着在模型前向传递期间对隐藏表示的修改。 **要理解 ReFT 的架构,我们首先考虑一个基于 Transformer 的语言模型,该模型生成标记序列的上下文化表示。** > 给定 n 个输入标记 x = (x₁, ..., xn) 的序列,模型首先将这些标记嵌入到表示形式列表中 h⁽⁰⁾ = (h₁⁽⁰⁾, ..., hn⁽⁰⁾)。然后,m 层连续计算第 j 个隐藏表示列表 h⁽j⁾ 作为前一个隐藏表示列表 h⁽j⁻¹⁾ 的函数。每个隐藏表示都是向量 h ∈ Rd,其中 d 是表示维数。 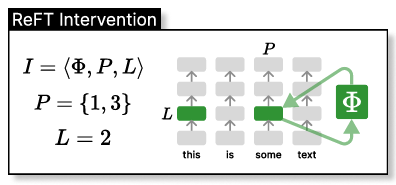 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) **ReFT 定义了干预的一般概念,它在模型的正向传递期间修改了隐藏的表示。** ## 介入: 干预 I 是一个元组 ⟨Φ, P, L⟩它封装了基于 Transformer 的 LM 计算的表示的单个推理时间修改。这三个组成部分是: - **干预函数 Φ:Rd → Rd,学习参数为 φ。** - **干预应用于的一组输入位置 P ⊆ {1, ..., n}。** - **层 L ∈ {1, ..., m},应用干预。** **干预 I 的实施方式如下:** > h⁽l⁾ ← (Φ(h_p⁽l⁾) if p ∈ P else h_p⁽l⁾)_{p∈1,...,n} 干预在计算 h⁽l⁾ 后立即应用,因此会影响后面的层 h⁽l⁺¹⁾, ..., h⁽m⁾ 中计算的表示。 # 低秩线性子空间 ReFT (LoReFT) 分布式交换干预 (DII) 提出了一种通过干预控制模型生成的方法。因此,指导直觉的是如何执行干预,使模型能够准确预测任务标签。 ## 低秩线性子空间 ReFT (LoReFT) 定义为: 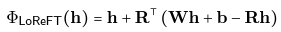 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) > 在方程中,它使用学习到的投影源 Rs = Wh + b。直观地说,LoReFT 编辑了由 R 列跨越的 r 维子空间中的表示,以采用从我们的线性投影 Wh +b 获得的值。 **对于生成任务,ReFT 论文使用语言建模的训练目标,重点是通过教师对所有输出位置的强迫来最小化交叉熵损失。**  由 Bing AI 创建 # pyreft:ReFT 原生 Python 库 为了促进 ReFT 模型的训练和共享,斯坦福大学的研究人员发布了 pyreft,这是一个基于 pyvene 构建的 Python 库,pyvene 是一个用于在任意 PyTorch 模型上执行和训练激活干预的库。 借助 pyreft,HuggingFace 上可用的任何预训练语言模型都可以使用 ReFT 方法进行微调,并且微调后的模型可以轻松上传到 HuggingFace。以下是如何对第 19 层的残差流输出进行单次干预来包装 Llama-2 7B 模型的示例: ``` import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1 ), } ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters() ``` 然后,可以使用提供的数据加载助手和 HuggingFace trainer 为下游任务训练包装的模型。 # 让我们尝试使用 ReFT 进行微调: ``` from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side=“right”, use_fast=False) tokenizer.pad_token = tokenizer.unk_token # 获取训练数据来训练我们的干预记住以下顺序 memo_sequence = “”“欢迎 加入斯坦福大学的自然语言处理小组! 我们是一个充满激情、包容的团队,由学生和教师、博士后 和研究工程师组成,他们共同研究使计算机 能够处理、生成和理解人类语言的算法。我们的兴趣非常 广泛,包括计算语言学的基础科学研究、 机器学习、人类语言技术的实际应用, 以及计算社会科学和认知 科学的跨学科工作。我们还开发了各种关于 NLP 的教育材料和 许多供社区使用的工具,包括处理 60 多种人类语言文本的 Stanza 工具包。 “”“ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=[”GO->“], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir=“./tmp”, learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train() ``` 完成训练后,您可以检查您的模型生成: ``` prompt = tokenizer(“GO->”, return_tensors=“pt”).to(“cuda”) base_unit_location = prompt[“input_ids”].shape[-1] - 1 # 最后一个位置 _, reft_response = reft_model.generate( prompt, unit_locations={“sources->base”: (None, [[[base_unit_location]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True)) ``` # 显著成果:LoReFT 在基准测试中的表现 为了充分了解 LoReFT 的强大功能和潜力,让我们探索一下它在各种 NLP 基准测试中的卓越表现,正如斯坦福大学的研究人员所展示的那样。 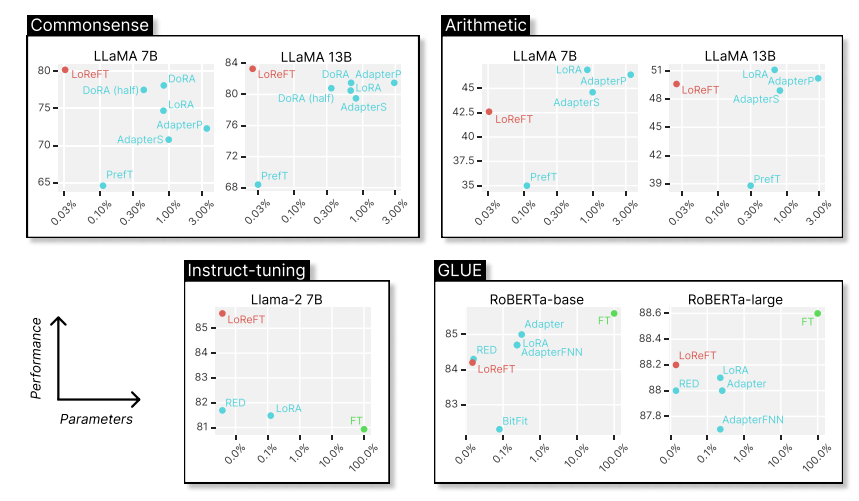 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) ## 1. 常识推理 LoReFT 在 BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e、ARC-c 和 OBQA 等八个具有挑战性的数据集上创下了最先进的新性能。尽管使用的参数明显少于现有的 PEFT 方法(少 10-50 倍),但 **LoReFT 的性能大大优于所有其他方法,展示了其有效捕获和利用大型语言模型中编码的常识知识的能力。** 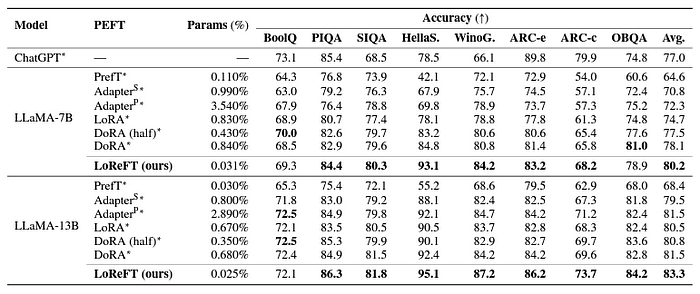 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) ## 2.算术推理 虽然 LoReFT 在算术推理任务上没有优于现有的 PEFT 方法,但它在 AQuA、GSM8K、MAWPS 和 SVAMP 等数据集上表现出有竞争力的性能。研究人员指出,LoReFT 的性能随着模型大小的增加而提高,这表明随着语言模型的不断增长,其功能可以很好地扩展。 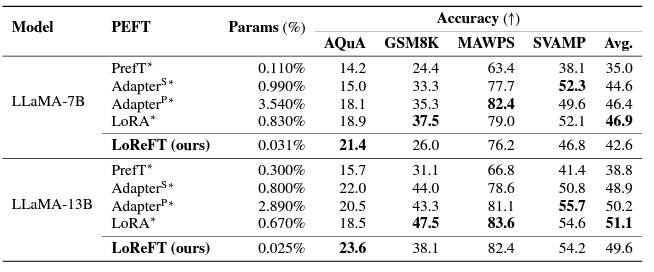 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) ## 3. 指令遵循 在后续教学领域,LoReFT 取得了显着的成果,在 Alpaca-Eval v1.0 基准测试中优于所有报告的微调方法,包括完全微调。当在 Llama-2 7B 模型上训练时,LoReFT 实现了强大的 GPT-3.5 Turbo 模型的 1% 以内的胜率,同时使用的参数比其他 PEFT 方法少得多。 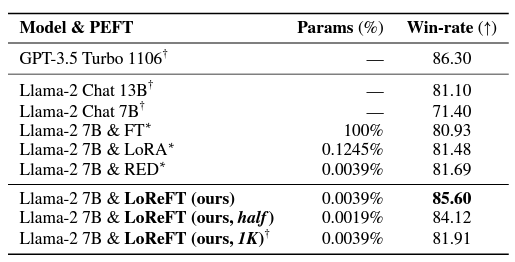 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) ## 4. 自然语言理解 LoReFT 还展示了其在自然语言理解任务中的能力,当应用于 RoBERTa-base 和 RoBERTa-large 模型时,在 GLUE 基准测试中实现了与现有 PEFT 方法相当的性能。 > 当参数计数与之前参数效率最高的 PEFT 方法匹配时,LoReFT 在各种任务中获得了相似的分数,包括情感分析和自然语言推理。 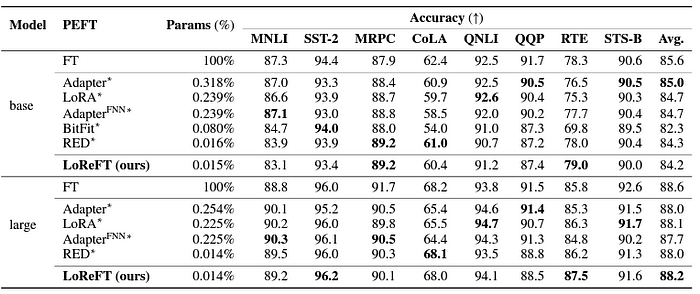 来源- [这里](https://arxiv.org/pdf/2404.03592v1.pdf) # ReFT 的未来:影响和应用 ReFT 的成功,尤其是 LoReFT,对自然语言处理的未来和大型语言模型的实际应用具有重大影响。 1. **高效的模型适应 :**ReFT 的参数效率使其成为一种有吸引力的解决方案,可以使大型语言模型适应特定任务或领域,同时最大限度地减少计算资源和训练时间。 2. **可解释性和可解释性 :** 除了其实用优势之外,ReFT 还提供了一个独特的机会来增强大型语言模型的可解释性和可解释性。 3. **实际应用:**ReFT 在常识推理、算术推理和指令遵循等任务中的成功表明了广泛的潜在实际应用。 # 结论:使用 ReFT 拥抱 NLP 的未来 ReFT 的出现,尤其是 LoReFT 方法,标志着自然语言处理领域的一个重要里程碑。通过提供一种更高效和有效的方法来适应大型语言模型,ReFT 有望解锁新的可能性并克服传统微调方法的局限性。 **SEO关键词:** ReFT NLP、LoReFT、参数高效微调、pyreft、ReFT 实现、算术推理 NLP、LoReFT 数学推理、自然语言理解 NLP、LoReFT 语言理解、常识推理 NLP、LoReFT  由 Bing AI 创建
yg9538
2024年12月9日 16:34
1580
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期