基于ShardingJDBC实现数据库读写分离

在大多数业务场景下,当我们的数据量达到一定数量级TB级或者PB级的时候,对数据的读写操作将会变得相当困难,这也将会造成系统性能瓶颈,系统的吞吐量将会明显降低。想要解决这一瓶颈问题,可能最简单的有三种解决方案:
增加单个数据库节点的CUP和内存数量;
采用分布式数据库,对数据进行分库分表;
采用简单的读写分离技术,降低单个数据库节点的负荷;
在上一篇文章ShardingJDBC实现多数据库节点分库分表 中,我将大致讲解了一下如何实现对数据库进行分库分表操作,本篇文章我们将大致讲解下如何通过ShardingJDBC对数据库进行读写分离操作。当然,关于读写分离的技术在实施的过程中有以下几种方法:
基于公有云(阿里云)的基础设施服务天然支持数据库的读写分离,只需对服务做简单的配置即可;
基于源代码的硬编码方式,采用双数据源(datasource);
基于中间件的方式,例如mycat等开源中间件;
基于数据源代理jar包+配置项的方式,例如:shardingsphere等;
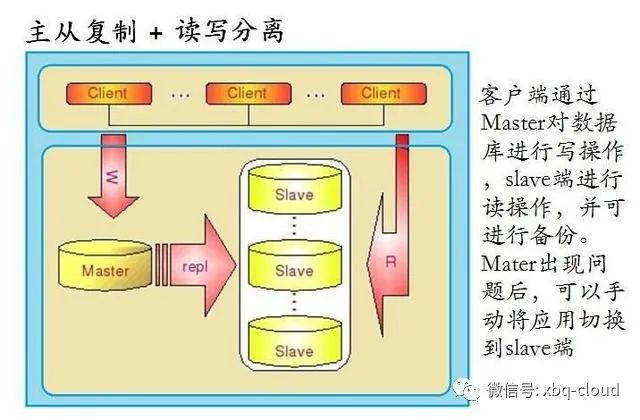
下面我们将通过一个例子大概讲解下,ShardingJDBC是如何实现数据库的读写分离,文末将添附源代码地址。

ShardingJDBC只能实现数据的读写分离技术,它不能实现数据库的主从复制功能,所以数据库的主从复制功能需要采用另外的技术实现,基于公有云数据库或者自己托管数据库对数据库进行主从复制配置。
一,首先我们采用Docker快速搭建一套数据库的主从复制环境,也可用参考这篇文章MySQL数据库读写分离技术实践 实施
Master数据库配置文件如下:
root@ubuntu18:~# cat master.cnf
[mysqld]
# master server id
server-id = 1
# bin log
log_bin = mysql-master-bin
Slave数据库配置文件如下:
root@ubuntu18:~# cat slave.cnf
[mysqld]
# slave server id
server-id = 2
# bin log
log_bin = mysql-slave-bin
relay_log = mysql-relay-bin
log_slave_updates = 1
read_only = 1
分别启动两个Docker数据库:
root@ubuntu18:~# docker run --name master -p 3310:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:master
d34d8767560b3f08e3eb4205ac80388456c546dde524c9c2707496f22e9c5523
root@ubuntu18:~# docker run --link master:master --name slave -p 3320:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:slave
664857039ab3a933ff7b12be50be36244ea14712d6dc2b495c815510acef7844
root@ubuntu18:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
664857039ab3 mysql:slave "docker-entrypoint.s…" 5 seconds ago Up 4 seconds 33060/tcp, 0.0.0.0:3320->3306/tcp slave
d34d8767560b mysql:master "docker-entrypoint.s…" 39 seconds ago Up 38 seconds 33060/tcp, 0.0.0.0:3310->3306/tcp master
master数据库暴露3310端口;
slave数据库暴露3320端口;
配置Master数据库:
mysql> create user 'repl'@'%' identified by 'repl-pwd';
Query OK, 0 rows affected (0.00 sec)
mysql> grant replication slave on *.* to 'repl'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> show master status;
+-------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------------+----------+--------------+------------------+-------------------+
| mysql-master-bin.000003 | 855 | | | |
+-------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> alter user 'repl'@'%' identified by 'repl-pwd' password expire never;
Query OK, 0 rows affected (0.01 sec)
mysql> alter user 'repl'@'%' identified with mysql_native_password by 'repl-pwd';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
配置Slave数据库:
mysql> change master to master_host='master', master_user='repl', master_password='repl-pwd', master_log_file='mysql-master-bin.000003', master_log_pos=0;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: master
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-master-bin.000003
Read_Master_Log_Pos: 1640
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 1869
Relay_Master_Log_File: mysql-master-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1640
Relay_Log_Space: 2078
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4143f5a8-0a10-11eb-8197-0242ac110003
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set (0.00 sec)
二,准备一张表结构如下:
create database ds;
use ds;
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE IF NOT EXISTS `t_order`
(
`order_id` INT UNSIGNED,
`order_name` VARCHAR(255) NOT NULL,
`order_date` VARCHAR(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;
三,新建一个SpringBoot项目:
ShardingJDBC配置项如下:
debug: true
spring:
shardingsphere:
datasource:
names: master,slave
master:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://10.0.0.8:3310/ds
username: root
password: root
slave:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://10.0.0.8:3320/ds
username: root
password: root
masterslave:
load-balance-algorithm-type: round_robin
name: ms
master-data-source-name: master
slave-data-source-names: slave
props:
sql:
show: true
management:
health:
db:
enabled: false
ShardingJDBC支持一主多从的场景,也就是说可以有多个slave数据库,但是只能存在一个master数据库;
从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM;
本例中我们采用一主一从的情况;
master数据库采用3310端口,slave数据库采用3320端口;
DAO层:
@Repository
public interface OrderRepository extends JpaRepository<OrderEntity, Integer> {
}
实体类:
@Data
@Entity
@Table(name = "t_order")
public class OrderEntity {
@Id
@Column(name = "order_id")
private int id;
@Column(name = "order_name")
private String name;
@Column(name = "order_date")
private String date;
}
Service层:
@Service
public class ShardingReadWriteService {
@Autowired
private OrderRepository orderRepository;
public void save(int i) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
OrderEntity orderEntity = new OrderEntity();
orderEntity.setId(i);
orderEntity.setName(UUID.randomUUID().toString());
orderEntity.setDate(sdf.format(new Date()));
orderRepository.save(orderEntity);
}
public List<OrderEntity> list() {
return orderRepository.findAll();
}
}
通过Junit进行测试:
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingReadWriteTest {
@Autowired
private ShardingReadWriteService shardingReadWriteService;
@Test
public void save() {
for (int i = 0; i < 100; i++) {
shardingReadWriteService.save(i);
}
System.out.println("save done!");
}
@Test
public void list() {
List<OrderEntity> list = shardingReadWriteService.list();
System.out.println(JSONArray.fromObject(list));
System.out.println("total count:" + list.size());
}
}

在IDEA中运行插入数据单元测试效果如下:
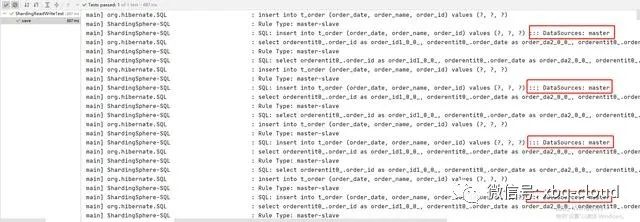
在IDEA中运行查询数据单元测试效果如下:

对比两个测试结果,我们可以清楚的发现:
当插入数据的时候,采用的是master数据源(master datasource);
当查询数据的时候,采用的是slave数据源(slave datasource);
参考:
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-spring-boot/#读写分离
demo源码:
https://github.com/bq-xiao/sharding-jdbc-demo.git
不积跬步,无以至千里;不积小流,无以成江海!