ShardingJDBC实现多数据库节点分库分表

在我们的实际工作中,我们可能会遇到TB级的数据量,也可能会遇到十亿级数据库记录的情况。在这种大数据量的情况下,无论是对数据进行计算处理,还是对数据存储都将是面临一种挑战。如果我们的应用系统的架构设计不是很合理,或者我们开发人员的技能水平不具备扎实的功底,可能面对这样庞大的数据量会感到无从下手。
面对这种海量数据,在关系型数据库领域,比如MySQL如何能够达到高效的存储和查询呢?
可能有以下几种方案:
-
分数据库节点和分库分表,将数据按照一定的规则均衡的分布到不同的数据库节点,在一个数据库节点上进行分库,同时在一个数据库中再次按照一定的规则进行分表,整个结构看起来就是一个树状结构;
-
进行读写分离,将数据的写入和查询操作分散到不同的数据库节点和数据库上;
-
采用中间件和缓存技术,将热点数据提前加载,每次查询从缓存中提取,减少对数据库的压力,提高查询速度;
在这种海量数据的情况下,分库分表可能是一种比较好的解决方案,可能也是大多数开发人员考虑的方案。这种分库分表的方案实施过程中可能有两种方法:
-
通过业务逻辑代码实现分库分表,这种方法对整个项目代码侵入比较多,如果后端更换数据库,可能需要修改分库分表的逻辑代码;
-
采用中间件实现分库分表,例如:sharding-jdbc,mycat等,这种方法对业务逻辑代码基本没有侵入,通过引入jar包或者maven dependency,再结合配置项实现;
下面我们通过一个简单的例子来学习下,sharding-jdbc如何实现分数据库节点和分库分表,并将整个过程记录下来方便以后查阅。

准备环境
我们的数据库拓扑图如下:
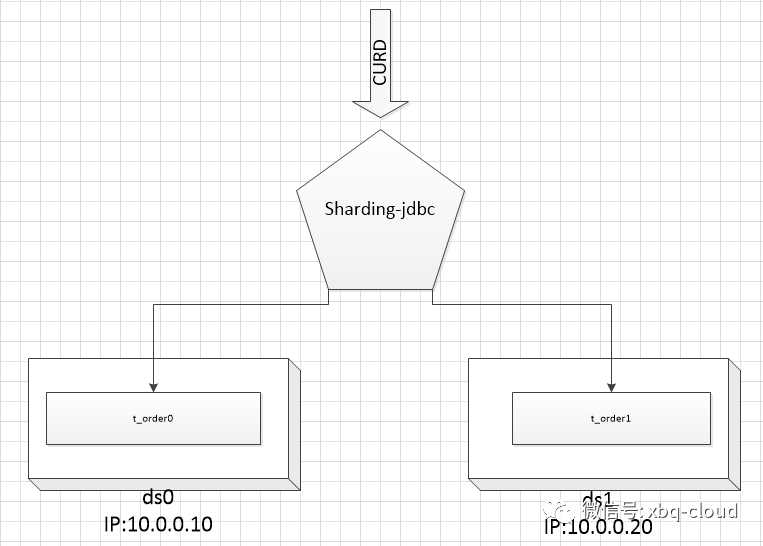
-
ds0数据库所在机器IP地址:
10.0.0.10;
-
ds1数据库所在机器IP地址:10.0.0.20;
-
ds0和ds1对t_order进行分表,分为t_order0和t_order1两张表;
-
通过sharding-jdbc中间件进行数据的分库和分表操作;
采用docker快速在10.0.0.10和10.0.0.20上分别构建两个数据库:
[root@instance01 ~]# docker pull mysql:5.7
[root@instance01 ~]# docker run --name ds0 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
[root@instance02 ~]# docker pull mysql:5.7
[root@instance02 ~]# docker run --name ds1 -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7在10.0.0.10数据库节点上导入如下表结构:
create database ds0;
use ds0;
DROP TABLE IF EXISTS `t_order0`;
CREATE TABLE IF NOT EXISTS `t_order0`
(
`order_id` INT UNSIGNED,
`order_name` VARCHAR(255) NOT NULL,
`order_date` VARCHAR(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;
DROP TABLE IF EXISTS `t_order1`;
CREATE TABLE IF NOT EXISTS `t_order1`
(
`order_id` INT UNSIGNED,
`order_name` VARCHAR(255) NOT NULL,
`order_date` VARCHAR(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;在10.0.0.20数据库节点上导入如下表结构:
create database ds1;
use ds1;
DROP TABLE IF EXISTS `t_order0`;
CREATE TABLE IF NOT EXISTS `t_order0`
(
`order_id` INT UNSIGNED,
`order_name` VARCHAR(255) NOT NULL,
`order_date` VARCHAR(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;
DROP TABLE IF EXISTS `t_order1`;
CREATE TABLE IF NOT EXISTS `t_order1`
(
`order_id` INT UNSIGNED,
`order_name` VARCHAR(255) NOT NULL,
`order_date` VARCHAR(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;构建SpringBoot工程
引入sharding-jdbc的maven dependency如下:
<properties>
<java.version>1.8</java.version>
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
</properties>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>配置sharding-jdbc properties文件内容如下:
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://10.0.0.10:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://10.0.0.20:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.binding-tables=t_order
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{order_id % 2}-
分别定义了两个datasource ds0和ds1;
-
对order表进行数据分表存储,数据分表算法是根据order表的主键order id进行取模运算;
-
分库策略同样是根据order表的主键order id进行取模运算;
定义一个Service,主要有两个方法向数据库写入数据和从数据库中查询数据:
@Service
public class ShardingService {
@Autowired
private OrderRepository orderRepository;
public void save(int i) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
OrderEntity orderEntity = new OrderEntity();
orderEntity.setId(i);
orderEntity.setName(UUID.randomUUID().toString());
orderEntity.setDate(sdf.format(new Date()));
orderRepository.save(orderEntity);
}
public List<OrderEntity> list() {
return orderRepository.findAll();
}
}这里主要使用SpringBoot的JPA进行数据库操作;
Order表的实体类如下:
@Data
@Entity
@Table(name = "t_order")
public class OrderEntity {
@Id
@Column(name = "order_id")
private int id;
@Column(name = "order_name")
private String name;
@Column(name = "order_date")
private String date;
}通过Junit进行测试:
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingJDBCTest {
@Autowired
private ShardingService shardingService;
@Test
public void save() {
for (int i = 0; i < 100; i++) {
shardingService.save(i);
}
System.out.println("save done!");
}
@Test
public void list() {
List<OrderEntity> list = shardingService.list();
System.out.println(JSONArray.fromObject(list));
}
}

验证
分别运行Junit的save方法和list方法:
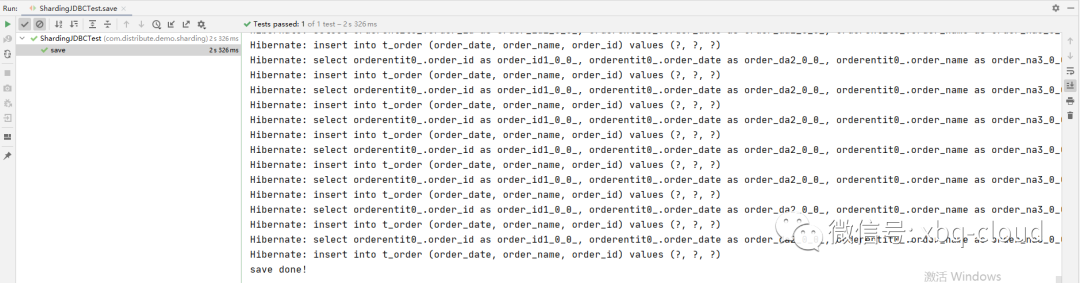
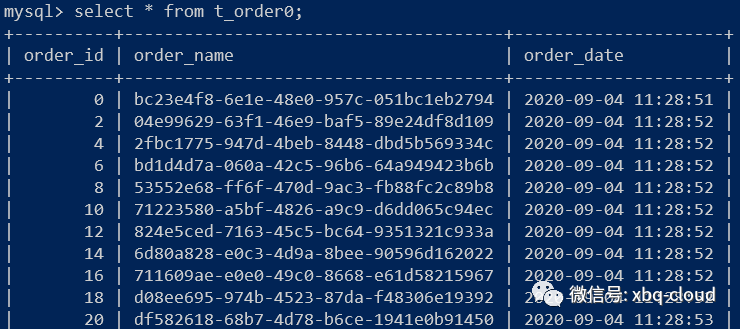
查询数据库数据结果如下:
ds0查询结果:
 ds1查询结果:
ds1查询结果:
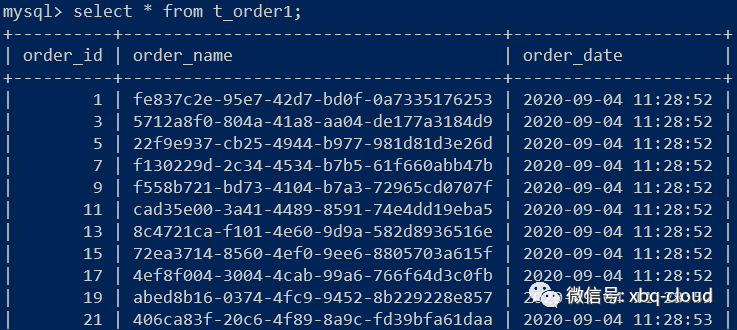
order id为偶数的数据存入数据库ds0中的t_order0表中,order id为奇数的数据存入数据库ds1中的t_order1表中。
验证结果:
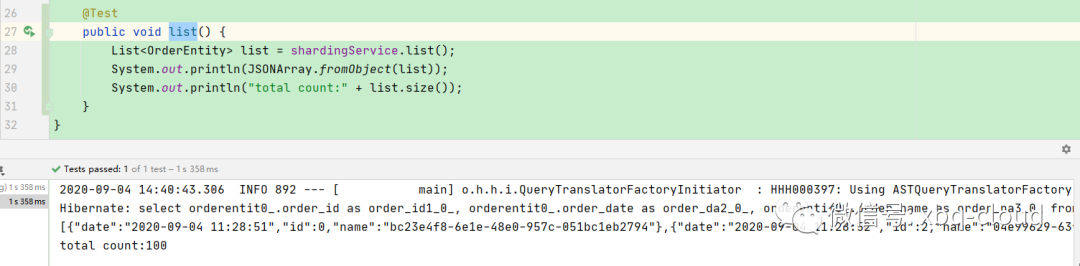 通过Junit的list方法我们可以看到一次将100条数据结果全部查询出来了。
通过Junit的list方法我们可以看到一次将100条数据结果全部查询出来了。
参考:
https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/configuration/config-spring-boot/
demo源码:
https://github.com/bq-xiao/sharding-jdbc-demo.git
不积跬步,无以至千里;不积小流,无以成江海!