Tips
Go
(18条消息) Go语言自学系列 | golang包_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发编程之channel的遍历_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发编程之select switch_COCOgsta的博客-CSDN博客_golang select switch
(18条消息) Go语言自学系列 | golang并发编程之runtime包_COCOgsta的博客-CSDN博客_golang runtime包
(18条消息) Go语言自学系列 | golang接口值类型接收者和指针类型接收者_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发编程之Timer_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang方法_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发编程之WaitGroup实现同步_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang构造函数_COCOgsta的博客-CSDN博客_golang 构造函数
(18条消息) Go语言自学系列 | golang方法接收者类型_COCOgsta的博客-CSDN博客_golang 方法接收者
(18条消息) Go语言自学系列 | golang接口_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang接口和类型的关系_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang结构体_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang结构体_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang标准库os模块 - File文件读操作_COCOgsta的博客-CSDN博客_golang os.file
(18条消息) Go语言自学系列 | golang继承_COCOgsta的博客-CSDN博客_golang 继承
(18条消息) Go语言自学系列 | golang嵌套结构体_COCOgsta的博客-CSDN博客_golang 结构体嵌套
(18条消息) Go语言自学系列 | golang并发编程之Mutex互斥锁实现同步_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发变成之通道channel_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang并发编程之原子操作详解_COCOgsta的博客-CSDN博客_golang 原子操作
(18条消息) Go语言自学系列 | golang并发编程之原子变量的引入_COCOgsta的博客-CSDN博客_go 原子变量
(18条消息) Go语言自学系列 | golang并发编程之协程_COCOgsta的博客-CSDN博客_golang 协程 并发
(18条消息) Go语言自学系列 | golang接口嵌套_COCOgsta的博客-CSDN博客_golang 接口嵌套
(18条消息) Go语言自学系列 | golang包管理工具go module_COCOgsta的博客-CSDN博客_golang 包管理器
(18条消息) Go语言自学系列 | golang标准库os模块 - File文件写操作_COCOgsta的博客-CSDN博客_go os模块
(18条消息) Go语言自学系列 | golang结构体的初始化_COCOgsta的博客-CSDN博客_golang 结构体初始化
(18条消息) Go语言自学系列 | golang通过接口实现OCP设计原则_COCOgsta的博客-CSDN博客
(18条消息) Go语言自学系列 | golang标准库os包进程相关操作_COCOgsta的博客-CSDN博客_golang os包
(18条消息) Go语言自学系列 | golang标准库ioutil包_COCOgsta的博客-CSDN博客_golang ioutil
(18条消息) Go语言自学系列 | golang标准库os模块 - 文件目录相关_COCOgsta的博客-CSDN博客_go语言os库
Golang技术栈,Golang文章、教程、视频分享!
(18条消息) Go语言自学系列 | golang结构体指针_COCOgsta的博客-CSDN博客_golang 结构体指针
go 协程泄漏 pprof
Ansible
太厉害了,终于有人能把Ansible讲的明明白白了,建议收藏_互联网老辛
ansible.cfg配置详解
Docker
Docker部署
linux安装docker和Docker Compose
linux 安装 docker
Docker中安装Docker遇到的问题处理
Docker常用命令
docker常用命令小结
docker 彻底卸载
Docker pull 时报错:Get https://registry-1.docker.io/v2/library/mysql: net/http: TLS handshake timeout
Docker 拉镜像无法访问 registry-x.docker.io 问题(Centos7)
docker 容器内没有权限
Linux中关闭selinux的方法是什么?
docker run 生成 docker-compose
Docker覆盖网络部署
docker pull后台拉取镜像
docker hub
docker 中启动 docker
docker in docker 启动命令
Redis
Redis 集群别乱搭,这才是正确的姿势
linux_离线_redis安装
怎么实现Redis的高可用?(主从、哨兵、集群) - 雨点的名字 - 博客园
redis集群离线安装
always-show-logo yes
Redis集群搭建及原理
[ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or contains some - 亲爱的不二999 - 博客园
Redis daemonize介绍
redis 下载地址
Redis的redis.conf配置注释详解(三) - 云+社区 - 腾讯云
Redis的redis.conf配置注释详解(一) - 云+社区 - 腾讯云
Redis的redis.conf配置注释详解(二) - 云+社区 - 腾讯云
Redis的redis.conf配置注释详解(四) - 云+社区 - 腾讯云
Linux
在终端连接ssh的断开关闭退出的方法
漏洞扫描 - 灰信网(软件开发博客聚合)
find 命令的参数详解
vim 编辑器搜索功能
非root安装rpm时,mockbuild does not exist
Using a SSH password instead of a key is not possible because Host Key checking
(9条消息) 安全扫描5353端口mDNS服务漏洞问题_NamiJava的博客-CSDN博客_5353端口
Linux中使用rpm命令安装rpm包
ssh-copy-id非22端口的使用方法
How To Resolve SSH Weak Key Exchange Algorithms on CentOS7 or RHEL7 - infotechys.com
Linux cp 命令
yum 下载全量依赖 rpm 包及离线安装(终极解决方案) - 叨叨软件测试 - 博客园
How To Resolve SSH Weak Key Exchange Algorithms on CentOS7 or RHEL7 - infotechys.com
RPM zlib 下载地址
运维架构网站
欢迎来到 Jinja2
/usr/local/bin/ss-server -uv -c /etc/shadowsocks-libev/config.json -f /var/run/s
ruby 安装Openssl 默认安装位置
Linux 常用命令学习 | 菜鸟教程
linux 重命名文件和文件夹
linux命令快速指南
ipvsadm
Linux 下查找日志中的关键字
Linux 切割大 log 日志
CentOS7 关于网络的设置
rsync 命令_Linux rsync 命令用法详解:远程数据同步工具
linux 可视化界面安装
[问题已处理]-执行yum卡住无响应
GCC/G++升级高版本
ELK
Docker部署ELK
ELK+kafka+filebeat+Prometheus+Grafana - SegmentFault 思否
(9条消息) Elasticsearch设置账号密码_huas_xq的博客-CSDN博客_elasticsearch设置密码
Elasticsearch 7.X 性能优化
Elasticsearch-滚动更新
Elasticsearch 的内存优化_大数据系统
Elasticsearch之yml配置文件
ES 索引为Yellow状态
Logstash:Grok filter 入门
logstash grok 多项匹配
Mysql
Mysql相关Tip
基于ShardingJDBC实现数据库读写分离 - 墨天轮
MySQL-MHA高可用方案
京东三面:我要查询千万级数据量的表,怎么操作?
OpenStack
(16条消息) openstack项目中遇到的各种问题总结 其二(云主机迁移、ceph及扩展分区)_weixin_34104341的博客-CSDN博客
OpenStack组件介绍
百度大佬OpenStack流程
openstack各组件介绍
OpenStack生产实际问题总结(一)
OpenStack Train版离线部署
使用Packstack搭建OpenStack
K8S
K8S部署
K8S 集群部署
kubeadm 重新 init 和 join-pudn.com
Kubernetes 实战总结 - 阿里云 ECS 自建 K8S 集群 Kubernetes 实战总结 - 自定义 Prometheus
【K8S实战系列-清理篇1】k8s docker 删除没用的资源
Flannel Pod Bug汇总
Pod创建流程代码版本[kubelet篇]
Java
Jdk 部署
JDK部署
java线程池ThreadPoolExecutor类使用详解 - bigfan - 博客园
ShardingJDBC实现多数据库节点分库分表 - 墨天轮
Maven Repository: Search/Browse/Explore
其他
Git在阿里,我们如何管理代码分支?
chrome F12调试网页出现Paused in debugger
体验IntelliJ IDEA的远程开发(Remote Development) - 掘金
Idea远程调试
PDF转MD
强哥分享干货
优秀开源项目集合
vercel 配合Github 搭建项目Doc门户
如何用 Github Issues 写技术博客?
Idea 2021.3 Maven 3.8.1 报错 Blocked mirror for repositories 解决
列出maven依赖
[2022-09 持续更新] 谷歌 google 镜像 / Sci-Hub 可用网址 / Github 镜像可用网址总结
阿里云ECS迁移
linux访问github
一文教你使用 Docker 启动并安装 Nacos-腾讯云开发者社区-腾讯云
远程本地多用户桌面1.17(一种不让电脑跟你抢键鼠的思路) - 哔哩哔哩
Nginx
Nginx 部署
Nginx 部署安装
Nginx反向代理cookie丢失的问题_longzhoufeng的博客-CSDN博客_nginx 代理后cookie丢失
Linux 系统 Https 证书生成与Nginx配置 https
数据仓库
实时数仓
松果出行 x StarRocks:实时数仓新范式的实践之路
实时数据仓库的一些分层和分层需要处理的事情,以及数据流向
湖仓一体电商项目
湖仓一体电商项目(一):项目背景和架构介绍
湖仓一体电商项目(二):项目使用技术及版本和基础环境准备
湖仓一体电商项目(三):3万字带你从头开始搭建12个大数据项目基础组件
数仓笔记
数仓学习总结
数仓常用平台和框架
数仓学习笔记
数仓技术选型
尚硅谷教程
尚硅谷学习笔记
尚硅谷所有已知的课件资料
尚硅谷大数据项目之尚品汇(11数据质量管理V4.0)
尚硅谷大数据项目之尚品汇(10元数据管理AtlasV4.0)
尚硅谷大数据项目之尚品汇(9权限管理RangerV4.0)
尚硅谷大数据项目之尚品汇(8安全环境实战V4.0)
尚硅谷大数据项目之尚品汇(7用户认证KerberosV4.1)
尚硅谷大数据项目之尚品汇(6集群监控ZabbixV4.1)
尚硅谷大数据项目之尚品汇(5即席查询PrestoKylinV4.0)
尚硅谷大数据项目之尚品汇(4可视化报表SupersetV4.0)
尚硅谷大数据项目之尚品汇(3数据仓库系统)V4.2.0
尚硅谷大数据项目之尚品汇(2业务数据采集平台)V4.1.0
尚硅谷大数据项目之尚品汇(1用户行为采集平台)V4.1.0
数仓治理
数据中台 元数据规范
数据中台的那些 “经验与陷阱”
2万字详解数据仓库数据指标数据治理体系建设方法论
数据仓库,为什么需要分层建设和管理? | 人人都是产品经理
网易数帆数据治理演进
数仓技术
一文看懂大数据生态圈完整知识体系
阿里云—升舱 - 数据仓库升级白皮书
最全企业级数仓建设迭代版(4W字建议收藏)
基于Hue,Dolphinscheduler,HIVE分析数据仓库层级实现及项目需求案例实践分析
详解数据仓库分层架构
数据仓库技术细节
大数据平台组件介绍
总览 2016-2021 年全球机器学习、人工智能和大数据行业技术地图
Apache DolphinScheduler 3.0.0 正式版发布!
数据仓库面试题——介绍下数据仓库
数据仓库为什么要分层,各层的作用是什么
Databend v0.8 发布,基于 Rust 开发的现代化云数据仓库 - OSCHINA - 中文开源技术交流社区
数据中台
数据中台设计
大数据同步工具之 FlinkCDC/Canal/Debezium 对比
有数数据开发平台文档
Shell
Linux Shell 命令参数
shell 脚本编程
一篇教会你写 90% 的 Shell 脚本
Kibana
Kibana 查询语言(KQL)
Kibana:在 Kibana 中的四种表格制作方式
Kafka
Kafka部署
canal 动态监控 Mysql,将 binlog 日志解析后,把采集到的数据发送到 Kafka
OpenApi
OpenAPI 标准规范,了解一下?
OpenApi学术论文
贵阳市政府数据开放平台设计与实现
OpenAPI简介
开放平台:运营模式与技术架构研究综述
管理
技术部门Leader是不是一定要技术大牛担任?
华为管理体系流程介绍
DevOps
*Ops
XOps 已经成为一个流行的术语 - 它是什么?
Practical Linux DevOps
Jenkins 2.x实践指南 (翟志军)
Jenkins 2权威指南 ((美)布伦特·莱斯特(Brent Laster)
DevOps组件高可用的思路
KeepAlived
VIP + KEEPALIVED + LVS 遇到Connection Peer的问题的解决
MinIO
MinIO部署
Minio 分布式集群搭建部署
Minio 入门系列【16】Minio 分片上传文件 putObject 接口流程源码分析
MinioAPI 浅入及问题
部署 minio 兼容 aws S3 模式
超详细分布式对象存储 MinIO 实战教程
Hadoop
Hadoop 部署
Hadoop集群部署
windows 搭建 hadoop 环境(解决 HADOOP_HOME and hadoop.home.dir are unset
Hadoop 集群搭建和简单应用(参考下文)
Hadoop 启动 NameNode 报错 ERROR: Cannot set priority of namenode process 2639
jps 命令查看 DataNode 进程不见了 (hadoop3.0 亲测可用)
hadoop 报错: Operation category READ is not supported in state standby
Spark
Spark 部署
Spark 集群部署
spark 心跳超时分析 Cannot receive any reply in 120 seconds
Spark学习笔记
apache spark - Failed to find data source: parquet, when building with sbt assembly
Spark Thrift Server 架构和原理介绍
InLong
InLong 部署
Apache InLong部署文档
安装部署 - Docker 部署 - 《Apache InLong v1.2 中文文档》 - 书栈网 · BookStack
基于 Apache Flink SQL 的 InLong Sort ETL 方案解析
关于 Apache Pulsar 在 Apache InLong 接入数据
zookeeper
zookeeper 部署
使用 Docker 搭建 Zookeeper 集群
美团技术团队
StarRocks
StarRocks技术白皮书(在线版)
JuiceFS
AI 场景存储优化:云知声超算平台基于 JuiceFS 的存储实践
JuiceFS 在 Elasticsearch/ClickHouse 温冷数据存储中的实践
JuiceFS format
元数据备份和恢复 | JuiceFS Document Center
JuiceFS 元数据引擎选型指南
Apache Hudi 使用文件聚类功能 (Clustering) 解决小文件过多的问题
普罗米修斯
k8s 之 Prometheus(普罗米修斯)监控,简单梳理下 K8S 监控流程
k8s 部署 - 使用helm3部署监控prometheus(普罗米修斯),从零到有,一文搞定
k8s 部署 - 使用 helm3 部署监控 prometheus(普罗米修斯),从零到有,一文搞定
k8s 部署 - 如何完善 k8s 中 Prometheus(普罗米修斯)监控项目呢?
k8s 部署 - k8s 中 Prometheus(普罗米修斯)的大屏展示 Grafana + 监控报警
zabbix
一文带你掌握 Zabbix 监控系统
Stream Collectors
Nvidia
Nvidia API
CUDA Nvidia驱动安装
NVIDIA驱动失效简单解决方案:NVIDIA-SMI has failed because it couldn‘t communicate with the NVIDIA driver.
ubuntu 20 CUDA12.1安装流程
nvidia开启持久化模式
nvidia-smi 开启持久化
Harbor
Harbor部署文档
Docker 爆出 it doesn't contain any IP SANs
pandoc
其他知识
大模型
COS 597G (Fall 2022): Understanding Large Language Models
如何优雅的使用各类LLM
ChatGLM3在线搜索功能升级
当ChatGLM3能用搜索引擎时
OCR神器,PDF、数学公式都能转
Stable Diffusion 动画animatediff-cli-prompt-travel
基于ERNIE Bot自定义虚拟数字人生成
pika负面提示词
开通GPT4的方式
GPT4网站
低价开通GPT Plus
大模型应用场景分享
AppAgent AutoGPT变体
机器学习
最大似然估计
权衡偏差(Bias)和方差(Variance)以最小化均方误差(Mean Squared Error, MSE)
伯努利分布
方差计算公式
均值的高斯分布估计
没有免费午餐定理
贝叶斯误差
非参数模型
最近邻回归
表示容量
最优容量
权重衰减
正则化项
Sora
Sora官方提示词
看完32篇论文,你大概就知道Sora如何炼成? |【经纬低调出品】
Sora论文
Sora 物理悖谬的几何解释
Sora 技术栈讨论
RAG垂直落地
DB-GPT与TeleChat-7B搭建相关RAG知识库
ChatWithRTX
ChatRTX安装教程
ChatWithRTX 踩坑记录
ChatWithRTX 使用其他量化模型
ChatWithRTX介绍
RAG 相关资料
英伟达—大模型结合 RAG 构建客服场景自动问答
又一大模型技术开源!有道自研RAG引擎QAnything正式开放下载
收藏!RAG入门参考资料开源大总结:RAG综述、介绍、比较、预处理、RAG Embedding等
RAG调研
解决现代RAG实际生产问题
解决现代 RAG 系统中的生产问题-II
Modular RAG and RAG Flow: Part Ⅰ
Modular RAG and RAG Flow: Part II
先进的Retriever技术来增强你的RAGs
高级RAG — 使用假设文档嵌入 (HyDE) 改进检索
提升 RAG:选择最佳嵌入和 Reranker 模型
LangGraph
增强型RAG:re-rank
LightRAG:使用 PyTorch 为 LLM 应用程序提供支持
RAG 101:分块策略
模型训练
GPU相关资料
[教程] conda安装简明教程(基于miniconda和Windows)
PyTorch CUDA对应版本 | PyTorch
资料
李一舟课程全集
零碎资料
苹果各服共享ID
数据中心网络技术概览
华为大模型训练学习笔记
百度AIGC工程师认证考试答案(可换取工信部证书)
百度智能云生成式AI认证工程师 考试和证书查询指南
深入理解 Megatron-LM(1)基础知识
QAnything
接入QAnything的AI问答知识库,可私有化部署的企业级WIKI知识库
wsl --update失效Error code: Wsl/UpdatePackage/0x80240438的解决办法
Docker Desktop 启动docker engine一直转圈解决方法
win10开启了hyper-v,docker 启动还是报错 docker desktop windows hypervisor is not present
WSL虚拟磁盘过大,ext4迁移 Windows 中创建软链接和硬链接
WSL2切换默认的Linux子系统
Windows的WSL子系统,自动开启sshd服务
新版docker desktop设置wsl(使用windown的子系统)
WSL 开启ssh
Windows安装网易开源QAnything打造智能客服系统
芯片
国内互联网大厂自研芯片梳理
超算平台—算力供应商
Linux 磁盘扩容
Linux使用growpart工具进行磁盘热扩容(非LVM扩容方式)
关于centos7 扩容提示no tools available to resize disk with 'gpt' - o夜雨随风o - 博客园
(小插曲)neo4j配置apoc插件后检查版本发现:Unknown function ‘apoc.version‘ “EXPLAIN RETURN apoc.version()“
KubeVirt
vnc server配置、启动、重启与连接 - 王约翰 - 博客园
虚拟机Bug解决方案
kubevirt 如何通过CDI上传镜像文件
在 K8S 上也能跑 VM!KubeVirt 簡介與建立(部署篇) | Cloud Solutions
KubeVirt 04:容器化数据导入 – 小菜园
Python
安装 flash_attn
手把手教你在linux上安装pytorch与cuda
AI
在启智社区基于PyTorch运行国产算力卡的模型训练实验
Scaling law
免费的GPT3.5 API
AI Engineer Roadmap & Resources 🤖
模型排行
edk2
K8S删除Evicted状态的pod
abrt-ccpp干崩服务器查询记录
kernel 各版本下载地址
2025 年工作
671B DeepSeek
cusor
文生图模型榜单
通用agent和垂直agent
Kubevirt
vfio-pci与igb_uio映射硬件资源到DPDK的流程分析
kubevirt 中文社区
VNCServer 连接方法
[译]深入剖析 Kubernetes MutatingAdmissionWebhook-腾讯云开发者社区-腾讯云
[译]深入剖析 Kubernetes MutatingAdmissionWebhook-腾讯云开发者社区-腾讯云
深入理解 Kubernetes Admission Webhook-阳明的博客
CentOS7 安装 mbedtls和mbedtls-devel
ssl
Caddy: 简化SSL证书管理的利器
ssl 证书续签
护网要求,MindIE 请登录后查看其他文集
ESP-IDF 安装指南
程序员智能体商业化接单实战:从技术宅男到副业月入 2 万的闭环之路
macos 蓝牙无限断开
MindStudio Insight 可视化调优工具试用版_MindStudio_昇腾论坛
服务化自动寻优工具使用过程记录_MindStudio_昇腾论坛
MindStudio Insight千卡数据使用案例_MindStudio_昇腾论坛
【重大更新】MindStudio Insight可视化调优工具介绍!!!(原Ascend Insight工具更名)_MindStudio_昇腾论坛
【MindStudio 训练营第一期】进阶班学习笔记-上_MindStudio_昇腾论坛
【MindStudio 训练营第一期】进阶班学习笔记-下_MindStudio_昇腾论坛
Atlas 800I A2部署funASR记录_昇腾主版块_昇腾论坛
昇腾300i duo推理卡适配 -- PaddleOCR
基于昇腾MindIE开箱部署Qwen2.5-VL-32B,体验更聪明的多模态理解能力
MindIE 2.1.rc1启动Qwen3-30B-A3B报错_MindIE_昇腾论坛
WSL安装英伟达驱动
MindIE 量化
npu-310b 相关的知识启动要是没有 npu-smi info 该咋办
寒武纪 vllm
310P1 的 mindie
MindIE 调整tokens
-
+
首页
湖仓一体电商项目(三):3万字带你从头开始搭建12个大数据项目基础组件
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [lansonli.blog.csdn.net](https://lansonli.blog.csdn.net/article/details/126006624)  **文章目录** [一、搭建 Zookeeper](#t0) [1、上传 zookeeper 并解压, 配置环境变量](#t1) [2、在 node3 节点配置 zookeeper](#t2) [3、将配置好的 zookeeper 发送到 node4,node5 节点](#t3) [4、各个节点上创建数据目录,并配置 zookeeper 环境变量](#t4) [5、各个节点创建节点 ID](#t5) [6、各个节点启动 zookeeper, 并检查进程状态](#t6) [二、搭建 HDFS](#t7) [1、各个节点安装 HDFS HA 自动切换必须的依赖](#t8) [2、上传下载好的 Hadoop 安装包到 node1 节点上,并解压](#t9) [3、在 node1 节点上配置 Hadoop 的环境变量](#t10) [4、配置 $HADOOP_HOME/etc/hadoop 下的 hadoop-env.sh 文件](#t11) [5、配置 $HADOOP_HOME/etc/hadoop 下的 hdfs-site.xml 文件](#t12) [6、配置 $HADOOP_HOME/ect/hadoop/core-site.xml](#t13) [7、配置 $HADOOP_HOME/etc/hadoop/yarn-site.xml](#t14) [8、配置 $HADOOP_HOME/etc/hadoop/mapred-site.xml](#t15) [9、配置 $HADOOP_HOME/etc/hadoop/workers 文件](#t16) [10、配置 $HADOOP_HOME/sbin/start-dfs.sh 和 stop-dfs.sh 两个文件中顶部添加以下参数,防止启动错误](#t17) [11、配置 $HADOOP_HOME/sbin/start-yarn.sh 和 stop-yarn.sh 两个文件顶部添加以下参数,防止启动错误](#t18) [12、将配置好的 Hadoop 安装包发送到其他 4 个节点](#t19) [13、在 node2、node3、node4、node5 节点上配置 HADOOP_HOME](#t20) [14、启动 HDFS 和 Yarn](#t21) [15、访问 WebUI](#t22) [16、停止集群](#t23) [三、搭建 Hive](#t24) [1、将下载好的 Hive 安装包上传到 node1 节点上, 并修改名称](#t25) [2、将解压好的 Hive 安装包发送到 node3 节点上](#t26) [3、配置 node1、node3 两台节点的 Hive 环境变量](#t27) [4、在 node1 节点 $HIVE_HOME/conf 下创建 hive-site.xml 并配置](#t28) [5、在 node3 节点 $HIVE_HOME/conf / 中创建 hive-site.xml 并配置](#t29) [6、node1、node3 节点删除 $HIVE_HOME/lib 下 “guava” 包,使用 Hadoop 下的包替换](#t30) [7、将 “mysql-connector-java-5.1.47.jar” 驱动包上传到 node1 节点的 $HIVE_HOME/lib 目录下](#t31) [8、在 node1 节点中初始化 Hive](#t32) [9、在服务端和客户端操作 Hive](#t33) [四、Hive 与 Iceberg 整合](#t34) [1、开启 Hive 支持 Iceberg](#t35) [2、Hive 中操作 Iceberg 格式表](#t36) [五、搭建 HBase](#t37) [1、将下载好的安装包发送到 node4 节点上, 并解压, 配置环境变量](#t38) [2、配置 $HBASE_HOME/conf/hbase-env.sh](#t39) [3、配置 $HBASE_HOME/conf/hbase-site.xml](#t40) [4、配置 $HBASE_HOME/conf/regionservers,配置 RegionServer 节点](#t41) [5、配置 backup-masters 文件](#t42) [6、复制 hdfs-site.xml 到 $HBASE_HOME/conf / 下](#t43) [7、将 HBase 安装包发送到 node3,node5 节点上,并在 node3,node5 节点上配置 HBase 环境变量](#t44) [8、重启 Zookeeper、重启 HDFS 及启动 HBase 集群](#t45) [9、测试 HBase 集群](#t46) [六、搭建 Phoenix](#t47) [1、下载 Phoenix](#t48) [2、上传解压](#t49) [3、拷贝 Phoenix 整合 HBase 需要的 jar 包](#t50) [4、复制 core-site.xml、hdfs-site.xml、hbase-site.xml 到 Phoenix](#t51) [5、启动 HDFS,Hbase 集群,启动 Phoenix](#t52) [6、测试 Phoenix](#t53) [七、搭建 Kafka](#t54) [1、上传解压](#t55) [2、配置 Kafka](#t56) [3、将以上配置发送到 node2,node3 节点上](#t57) [4、修改 node2,node3 节点上的 server.properties 文件](#t58) [5、创建 Kafka 启动脚本](#t59) [6、启动 Kafka 集群](#t60) [7、Kafka 命令测试](#t61) [八、搭建 Redis](#t62) [1、将 redis 安装包上传到 node4 节点,并解压](#t63) [2、node4 安装需要的 C 插件](#t64) [3、编译 Redis](#t65) [4、创建安装目录安装 Redis](#t66) [5、将 Redis 加入环境变量,加入系统服务,设置开机启动](#t67) [6、配置 Redis 环境变量](#t68) [7、启动 | 停止 Redis 服务](#t69) [8、测试 redis](#t70) [九、搭建 Flink](#t71) [1、上传压缩包解压](#t72) [2、修改配置文件](#t73) [3、配置 TaskManager 节点](#t74) [4、分发安装包到 node2,node3,node4 节点](#t75) [5、启动 Flink 集群](#t76) [6、访问 flink Webui](#t77) [7、准备 “flink-shaded-hadoop-2-uber-2.8.3-10.0.jar” 包](#t78) [十、搭建 Flume](#t79) [1、首先将 Flume 上传到 Mynode5 节点 / software / 路径下, 并解压,命令如下:](#t80) [2、其次配置 Flume 的环境变量,配置命令如下:](#t81) [十一、搭建 maxwell](#t82) [1、开启 MySQL binlog 日志](#t83) [2、安装 Maxwell](#t84) [十二、搭建 clickhouse](#t85) [1、选择三台 clickhouse 节点,在每台节点上安装 clickhouse 需要的安装包](#t86) [2、安装 zookeeper 集群并启动](#t87) [3、配置外网可访问](#t88) [4、在每台节点创建 metrika.xml 文件,写入以下内容](#t89) [5、在每台节点上启动 / 查看 / 重启 / 停止 clickhouse 服务](#t90) [6、检查集群配置是否完成](#t91) [7、测试 clickhouse](#t92) 上篇已经大概讲述[大数据](https://so.csdn.net/so/search?q=%E5%A4%A7%E6%95%B0%E6%8D%AE&spm=1001.2101.3001.7020)组件版本和集群矩阵配置说明,有不清楚的同学,可以阅读上一篇 [湖仓一体电商项目(二):项目使用技术及版本和基础环境准备_Lansonli 的博客 - CSDN 博客](https://blog.csdn.net/xiaoweite1/article/details/125967399?spm=1001.2014.3001.5501 "湖仓一体电商项目(二):项目使用技术及版本和基础环境准备_Lansonli的博客-CSDN博客") 接下带大家一一搭建项目基础组件 **一、搭建 Zookeeper** ------------------ 这里搭建 zookeeper 版本为 3.4.13,搭建 zookeeper 对应的角色分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Zookeeper</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td><p>★</p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td><p>★</p></td></tr><tr><td><p>192.168.179.8</p></td><td><p>node5</p></td><td><p>★</p></td></tr></tbody></table> 具体搭建步骤如下: ### ****1、上传 zookeeper 并解压, 配置环境变量**** 在 node1,node2,node3,node4,node5 各个节点都创建 / software 目录,方便后期安装技术组件使用。 ``` #进入vim /etc/profile,在最后加入: export ZOOKEEPER_HOME=/software/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin #使配置生效 source /etc/profile ``` 将 zookeeper 安装包上传到 node3 节点 / software 目录下并解压: ``` [root@node3 software]# scp -r ./zookeeper-3.4.13 node4:/software/ [root@node3 software]# scp -r ./zookeeper-3.4.13 node5:/software/ ``` 在 node3 节点配置环境变量: ``` #进入vim /etc/profile,在最后加入: export ZOOKEEPER_HOME=/software/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin #使配置生效 source /etc/profile ``` ### **2、在 node3 节点配置 zookeeper** 进入 “/software/zookeeper-3.4.13/conf” 修改 zoo_sample.cfg 为 zoo.cfg ``` #各个节点启动zookeeper命令 zkServer.sh start #检查各个节点zookeeper进程状态 zkServer.sh status ``` 配置 zoo.cfg 中内容如下: tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/data/zookeeper clientPort=2181 server.1=node3:2888:3888 server.2=node4:2888:3888 server.3=node5:2888:3888 ### **3、将配置好的 zookeeper 发送到 node4,node5 节点** ``` [root@node1 software]# vim /etc/profile export HADOOP_HOME=/software/hadoop-3.1.4/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin: #使配置生效 source /etc/profile ``` ### **4、各个节点上创建数据目录,并配置 zookeeper 环境变量** 在 node3,node4,node5 各个节点上创建 zoo.cfg 中指定的数据目录 “/opt/data/zookeeper”。 ``` <configuration> <property> <!--这里配置逻辑名称,可以随意写 --> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <!-- 禁用权限 --> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <!-- 配置namenode 的名称,多个用逗号分割 --> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <property> <!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property> <property> <!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value> </property> <property> <!-- namenode高可用代理类 --> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!-- 使用ssh 免密码自动登录 --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <!-- journalnode 存储数据的地方 --> <name>dfs.journalnode.edits.dir</name> <value>/opt/data/journal/node/local/data</value> </property> <property> <!-- 配置namenode自动切换 --> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration> ``` 在 node4,node5 节点配置 zookeeper 环境变量 ``` <configuration> <property> <!-- 为Hadoop 客户端配置默认的高可用路径 --> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可 namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data --> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop/</value> </property> <property> <!-- 指定zookeeper所在的节点 --> <name>ha.zookeeper.quorum</name> <value>node3:2181,node4:2181,node5:2181</value> </property> </configuration> ``` ### **5、各个节点创建节点 ID** 在 node3,node4,node5 各个节点路径 “/opt/data/zookeeper” 中添加 myid 文件分别写入 1,2,3: #在 node3 的 / opt/data/zookeeper 中创建 myid 文件写入 1 #在 node4 的 / opt/data/zookeeper 中创建 myid 文件写入 2 #在 node5 的 / opt/data/zookeeper 中创建 myid 文件写入 3 ### **6、各个节点启动 zookeeper, 并检查进程状态** ``` <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <!-- 配置yarn为高可用 --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 集群的唯一标识 --> <name>yarn.resourcemanager.cluster-id</name> <value>mycluster</value> </property> <property> <!-- ResourceManager ID --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <!-- 指定ResourceManager 所在的节点 --> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <!-- 指定ResourceManager 所在的节点 --> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <property> <!-- 指定ResourceManager Http监听的节点 --> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node1:8088</value> </property> <property> <!-- 指定ResourceManager Http监听的节点 --> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node2:8088</value> </property> <property> <!-- 指定zookeeper所在的节点 --> <name>yarn.resourcemanager.zk-address</name> <value>node3:2181,node4:2181,node5:2181</value> </property> <property> <!-- 关闭虚拟内存检查 --> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 启用节点的内容和CPU自动检测,最小内存为1G --> <!--<property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>true</value> </property>--> </configuration> ``` **二、搭建 HDFS** ------------- 这里搭建 HDFS 版本为 3.1.4,搭建 HDFS 对应的角色在各个节点分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>NN</strong></strong></p></td><td><p><strong><strong>DN</strong></strong></p></td><td><p><strong><strong>ZKFC</strong></strong></p></td><td><p><strong><strong>JN</strong></strong></p></td><td><p><strong><strong>RM</strong></strong></p></td><td><p><strong><strong>NM</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td></tr><tr><td><p>192.168.179.8</p></td><td><p>node5</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td><td></td><td><p>★</p></td></tr></tbody></table> **搭建具体步骤如下:** ### **1、各个节点安装 HDFS HA 自动切换必须的依赖** ``` <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> ``` ### **2、上传下载好的 Hadoop 安装包到 node1 节点上,并解压** ``` [root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workers node3 node4 node5 ``` ### **3、在 node1 节点上配置 Hadoop 的环境变量** ``` [root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/ [root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/ [root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/ [root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/ ``` ### **4、配置 $HADOOP_HOME/etc/hadoop 下的 hadoop-env.sh 文件** #导入 JAVA_HOME ****export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/**** ### **5、配置 $HADOOP_HOME/etc/hadoop 下的 hdfs-site.xml 文件** ``` #分别在node2、node3、node4、node5节点上配置HADOOP_HOME vim /etc/profile export HADOOP_HOME=/software/hadoop-3.1.4/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin: #最后记得Source source /etc/profile ``` ### **6、配置 $HADOOP_HOME/ect/hadoop/core-site.xml** ``` #在node3,node4,node5节点上启动zookeeper zkServer.sh start #在node1上格式化zookeeper [root@node1 ~]# hdfs zkfc -formatZK #在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动 hdfs --daemon start journalnode #在node1中格式化namenode [root@node1 ~]# hdfs namenode -format #在node1中启动namenode,以便同步其他namenode [root@node1 ~]# hdfs --daemon start namenode #高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行): [root@node2 software]# hdfs namenode -bootstrapStandby #node1上启动HDFS,启动Yarn [root@node1 sbin]# start-dfs.sh [root@node1 sbin]# start-yarn.sh ``` ### **7、配置 $HADOOP_HOME/etc/hadoop/yarn-site.xml** ``` #停止集群 [root@node1 ~]# stop-dfs.sh [root@node1 ~]# stop-yarn.sh ``` ### **8、配置 $HADOOP_HOME/etc/hadoop/mapred-site.xml** ``` [root@node1 ~]# cd /software/ [root@node1 software]# tar -zxvf ./apache-hive-3.1.2-bin.tar.gz [root@node1 software]# mv apache-hive-3.1.2-bin hive-3.1.2 ``` ### **9、配置 $HADOOP_HOME/etc/hadoop/workers 文件** ``` vim /etc/profile export HIVE_HOME=/software/hive-3.1.2/ export PATH=$PATH:$HIVE_HOME/bin #source 生效 source /etc/profile ``` ### **10、配置 $HADOOP_HOME/sbin/start-dfs.sh 和 stop-dfs.sh 两个文件中顶部添加以下参数,防止启动错误** HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root ### **11、配置 $HADOOP_HOME/sbin/start-yarn.sh 和 stop-yarn.sh 两个文件顶部添加以下参数,防止启动错误** YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root ### **12、将配置好的 Hadoop 安装包发送到其他 4 个节点** ``` <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> </configuration> ``` ### **13、在 node2、node3、node4、node5 节点上配置 HADOOP_HOME** ``` <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> </configuration> ``` ### **14、启动 HDFS 和 Yarn** ``` #删除Hive lib目录下“guava-19.0.jar ”包 [root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar [root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar #将Hadoop lib下的“guava”包拷贝到Hive lib目录下 [root@node1 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/ [root@node3 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/ ``` 注意以上也可以使用 start-all.sh 命令启动 Hadoop 集群。 ### **15、访问 WebUI** 访问 HDFS : http://node1:50070 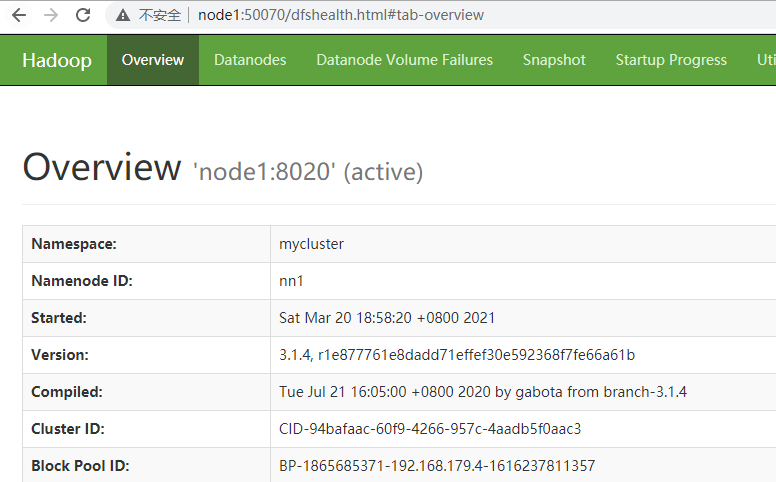 访问 Yarn WebUI :http://node1:8088 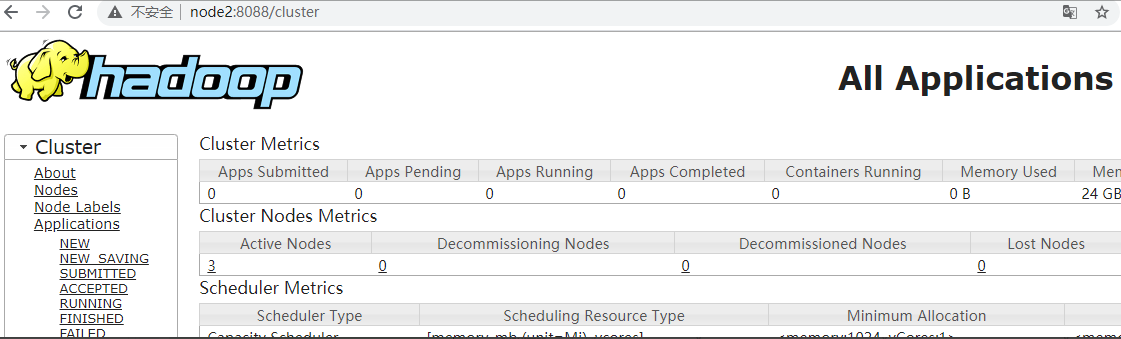 ### **16、停止集群** ``` #初始化hive,hive2.x版本后都需要初始化 [root@node1 ~]# schematool -dbType mysql -initSchema ``` 注意:以上也可以使用 stop-all.sh 停止集群。 **三、搭建 Hive** --------------------------- 这里搭建 Hive 的版本为 3.1.2,搭建 Hive 的节点划分如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Hive 服务器</strong></strong></p></td><td><p><strong><strong>Hive 客户端</strong></strong></p></td><td><p><strong><strong>MySQL</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td><p>★</p></td><td></td><td></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td></td><td></td><td><p>★(已搭建)</p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td></td><td><p>★</p></td><td></td></tr></tbody></table> **搭建具体步骤如下:** ### **1、将下载好的 Hive 安装包上传到 node1 节点上, 并修改名称** ``` #在node1中登录Hive ,创建表test [root@node1 conf]# hive hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t'; #向表test中插入数据 hive> insert into test values(1,"zs",18); #在node1启动Hive metastore [root@node1 hadoop]# hive --service metastore & #在node3上登录Hive客户端查看表数据 [root@node3 lib]# hive hive> select * from test; OK 1 zs 18 ``` ### **2、将解压好的 Hive 安装包发送到 node3 节点上** ``` <property> <name>iceberg.engine.hive.enabled</name> <value>true</value> </property> ``` ### **3、配置 node1、node3 两台节点的 Hive 环境变量** ``` create table test_iceberg_tbl1( id int , name string, age int) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'; ``` ### **4、在 node1 节点 $HIVE_HOME/conf 下创建 hive-site.xml 并配置** ``` hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; ``` ### **5、在 node3 节点 $HIVE_HOME/conf / 中创建 hive-site.xml 并配置** ``` hive> select * from test_iceberg_tbl1; OK 1 zs 18 20211212 ``` ### **6、node1、node3 节点删除 $HIVE_HOME/lib 下 “guava” 包,使用 Hadoop 下的包替换** ``` create table test_iceberg_tbl2( id int, name string, age int ) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' tblproperties ('iceberg.catalog'='another_hive'); ``` ### **7、将 “mysql-connector-java-5.1.47.jar” 驱动包上传到 node1 节点的 $HIVE_HOME/lib 目录下** 上传后,需要将 mysql 驱动包传入 $HIVE_HOME/lib / 目录下,这里 node1,node3 节点都需要传入。 ### **8、在 node1 节点中初始化 Hive** ``` hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; ``` ### **9、在服务端和客户端操作 Hive** ``` hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212"); hive> select * from test_iceberg_tbl2; OK 2 ls 20 20211212 ``` **四、Hive 与 Iceberg 整合** ----------------------- Iceberg 就是一种表格式,支持使用 Hive 对 Iceberg 进行读写操作,但是对 Hive 的版本有要求,如下: <table><tbody><tr><td><p><strong><strong>操作</strong></strong></p></td><td><p><strong><strong>Hive 2.x</strong></strong></p></td><td><p><strong><strong>Hive 3.1.2</strong></strong></p></td></tr><tr><td><p><strong><strong>CREATE EXTERNAL TABLE</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td></tr><tr><td><p><strong><strong>CREATE TABLE</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td></tr><tr><td><p><strong><strong>DROP TABLE</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td></tr><tr><td><p><strong><strong>SELECT</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td></tr><tr><td><p><strong><strong>INSERT INTO</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td><td><p><strong><strong>√</strong></strong></p></td></tr></tbody></table> 这里基于 Hive3.1.2 版本进行 Hive 集成 Iceberg。 ### **1、开启 Hive 支持 Iceberg** **1.1、下载 iceberg-hive-runtime.jar** 想要使用 Hive 支持查询 Iceberg 表,首先需要下载 “iceberg-hive-runtime.jar”,Hive 通过该 Jar 可以加载 Hive 或者更新 Iceberg 表元数据信息。下载地址:https://iceberg.apache.org/#releases/  将以上 jar 包下载后,上传到 Hive 服务端和客户端对应的 $HIVE_HOME/lib 目录下。另外在向 Hive 中 Iceberg 格式表插入数据时需要到 “libfb303-0.9.3.jar” 包,将此包也上传到 Hive 服务端和客户端对应的 $HIVE_HOME/lib 目录下。 **1.2、配置 hive-site.xml** 在 Hive 客户端 $HIVE_HOME/conf/hive-site.[xml](https://so.csdn.net/so/search?q=xml&spm=1001.2101.3001.7020) 中追加如下配置: ``` create external table test_iceberg_tbl3( id int, name string, age int ) partitioned by (dt string) stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' location 'hdfs://mycluster/iceberg_data/default/test_iceberg_tbl3' tblproperties ('iceberg.catalog'='hadoop'); ``` ### **2、Hive 中操作 Iceberg 格式表** 从 Hive 引擎的角度来看,在运行环境中有 Catalog 概念(catalog 主要描述了数据集的位置信息,就是元数据),Hive 与 Iceberg 整合时,Iceberg 支持多种不同的 Catalog 类型,例如: Hive、Hadoop、第三方厂商的 AWS Glue 和自定义 Catalog。在实际应用场景中,Hive 可能使用上述任意 Catalog,甚至跨不同 Catalog 类型 join 数据,为此 Hive 提供了 org.apache.iceberg.mr.hive.HiveIcebergStorageHandler(位于包 iceberg-hive-runtime.jar)来支持读写 Iceberg 表,并通过在 Hive 中设置 “iceberg.catalog.<catalog_name>.type” 属性来决定加载 Iceberg 表的方式,该属性可以配置:hive、hadoop,其中 “<catalog_name>” 是自己随便定义的名称,主要是在 hive 中创建 Iceberg 格式表时配置 iceberg.catalog 属性使用。 在 Hive 中创建 Iceberg 格式表时,根据创建 Iceberg 格式表时是否指定 iceberg.catalog 属性值,有以下三种方式决定 Iceberg 格式表如何加载(数据存储在什么位置)。 **2.1、**如果没有设置 iceberg.catalog 属性,默认使用 HiveCatalog 来加载**** 这种方式就是说如果在 Hive 中创建 Iceberg 格式表时,不指定 iceberg.catalog 属性,那么数据存储在对应的 hive warehouse 路径下。 在 Hive 客户端 node3 节点进入 Hive,操作如下: ****在 Hive 中创建 iceberg 格式表**** ``` hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar; hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar; ``` ****在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到**** ``` hive> insert into test_iceberg_tbl3 values (3,"ww",20,"20211213"); hive> select * from test_iceberg_tbl3; OK 3 ww 20 20211213 ``` ****向表中插入数据**** ``` CREATE TABLE test_iceberg_tbl4 ( id int, name string, age int, dt string )STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler' LOCATION 'hdfs://mycluster/spark/person' TBLPROPERTIES ('iceberg.catalog'='location_based_table'); ``` ****查询表中的数据**** ``` #将下载好的HBase安装包上传至node4节点/software下,并解压 [root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz ``` 在 Hive 默认的 warehouse 目录下可以看到创建的表目录: 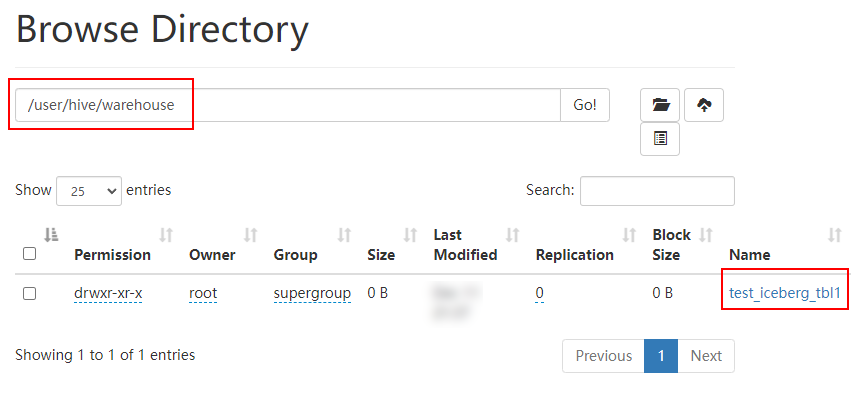 **2.2、如果设置了 iceberg.catalog 对应的 catalog 名字,就用对应类型的 catalog 加载** 这种情况就是说在 Hive 中创建 Iceberg 格式表时,如果指定了 iceberg.catalog 属性值,那么数据存储在指定的 catalog 名称对应配置的目录下。 在 Hive 客户端 node3 节点进入 Hive,操作如下: ****注册一个 HiveCatalog 叫 another_hive**** ``` #配置HBase环境变量 [root@node4 software]# vim /etc/profile export HBASE_HOME=/software/hbase-2.2.6/ export PATH=$PATH:$HBASE_HOME/bin #使环境变量生效 [root@node4 software]# source /etc/profile ``` ****在 Hive 中创建 iceberg 格式表**** ``` <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node3,node4,node5</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> ``` ****在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到**** ``` #创建 $HBASE_HOME/conf/backup-masters 文件,写入node5 [root@node4 conf]# vim backup-masters node5 ``` ****插入数据,并查询**** ``` [root@node4 software]# cd /software [root@node4 software]# scp -r ./hbase-2.2.6 node3:/software/ [root@node4 software]# scp -r ./hbase-2.2.6 node5:/software/ # 注意:在node3、node5上配置HBase环境变量。 vim /etc/profile export HBASE_HOME=/software/hbase-2.2.6/ export PATH=$PATH:$HBASE_HOME/bin #使环境变量生效 source /etc/profile ``` 以上方式指定 “iceberg.catalog.****another_hive****.type=hive” 后,实际上就是使用的 hive 的 catalog,这种方式与第一种方式不设置效果一样,创建后的表存储在 hive 默认的 warehouse 目录下。也可以在建表时指定 location 写上路径,将数据存储在自定义对应路径上。 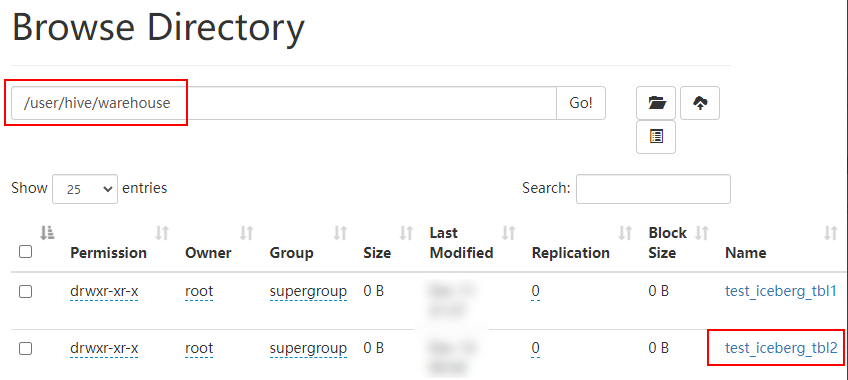 除了可以将 catalog 类型指定成 hive 之外,还可以指定成 hadoop,在 Hive 中创建对应的 iceberg 格式表时需要指定 location 来指定 iceberg 数据存储的具体位置,这个位置是****具有一定格式规范****的自定义路径。在 Hive 客户端 node3 节点进入 Hive,操作如下: ****注册一个 HadoopCatalog 叫 hadoop**** ``` #注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群 [root@node4 software]# start-hbase.sh ``` ****使用 HadoopCatalog 时,必须设置 “iceberg.catalog.<catalog_name>.warehouse” 指定 warehouse 路径**** ``` #进入hbase [root@node4 ~]# hbase shell #创建表test create 'test','cf1','cf2' #查看创建的表 list #向表test中插入数据 put 'test','row1','cf1:id','1' put 'test','row1','cf1:name','zhangsan' put 'test','row1','cf1:age',18 #查询表test中rowkey为row1的数据 get 'test','row1' ``` ****在 Hive 中创建 iceberg 格式表, 这里创建成外表**** ``` [root@node4 ~]# cd /software/ [root@node4 software]# tar -zxvf ./apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz ``` ****注意:以上 location 指定的路径必须是 “iceberg.catalog.hadoop.warehouse” 指定路径的子路径, 格式必须是 ${iceberg.catalog.hadoop.warehouse}/${当前建表使用的 hive 库}/${创建的当前 iceberg 表名}**** ****在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到**** ``` [root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin #直接复制到node4节点对应的HBase目录下 [root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# cp ./phoenix-*.jar /software/hbase-2.2.6/lib/ #发送到node3,node5两台HBase节点 [root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node3:/software/hbase-2.2.6/lib/ [root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node5:/software/hbase-2.2.6/lib/ ``` ****插入数据,并查询**** ``` [root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/core-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin [root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin #输入yes,覆盖Phoenix目录下的hbase-site.xml [root@node4 ~]# cp /software/hbase-2.2.6/conf/hbase-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/ ``` 在指定的 “iceberg.catalog.****hadoop****.warehouse” 路径下可以看到创建的表目录: 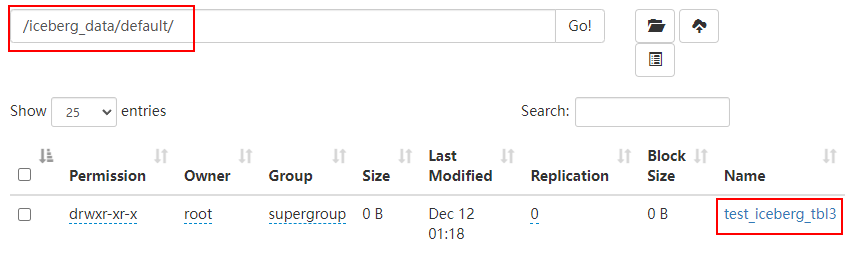 **2.3、如果 iceberg.catalog 属性设置为 “location_based_table”, 可以从指定的根路径下加载 Iceberg 表** 这种情况就是说如果 HDFS 中已经存在 iceberg 格式表,我们可以通过在 Hive 中创建 Icerberg 格式表指定对应的 location 路径映射数据。 在 Hive 客户端中操作如下: ``` [root@node1 ~]# start-all.sh [root@node4 ~]# start-hbase.sh (如果已经启动Hbase,一定要重启HBase) #启动Phoenix [root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/ #启动时可以不指定后面的zookeeper,默认连接当前节点的zookeeper,多个zookeeper节点逗号隔开,最后一个写端口2181 [root@node4 bin]# ./sqlline.py node3,node4,node5:2181 #退出Phoenix,使用!quit或者!exit 0: jdbc:phoenix:node3,node4,node5:2181> !quit Closing: org.apache.phoenix.jdbc.PhoenixConnection ``` ****注意:指定的 location 路径下必须是 iceberg 格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到 Hive iceberg 格式表。**** 由于 Hive 建表语句分区语法 “Partitioned by” 的限制, 如果使用 Hive 创建 Iceberg 格式表,目前只能按照 Hive 语法来写,底层转换成 Iceberg 标识分区,这种情况下不能使用 Iceberge 的分区转换,例如:days(timestamp),如果想要使用 Iceberg 格式表的分区转换标识分区,需要使用 Spark 或者 Flink 引擎创建表。 五、******搭建 HBase****** ----------------------------- 这里选择 HBase 版本为 2.2.6,搭建 HBase 各个角色分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>HBase 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td><p>RegionServer</p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td><p>HMaster,RegionServer</p></td></tr><tr><td><p>192.168.179.8</p></td><td><p>node5</p></td><td><p>RegionServer</p></td></tr></tbody></table> **具体搭建步骤如下:** ### **1、将下载好的安装包发送到 node4 节点上, 并解压, 配置环境变量** ``` #查看Phoenix表 0: jdbc:phoenix:node3,node4,node5:2181> !tables #Phoenix中创建表 test,指定映射到HBase的列族为f1 0: jdbc:phoenix:node3,node4,node5:2181> create table test(id varchar primary key ,f1.name varchar,f1.age integer); #向表 test中插入数据 upsert into test values ('1','zs',18); #查询插入的数据 0: jdbc:phoenix:node3,node4,node5:2181> select * from test; +-----+-------+------+ | ID | NAME | AGE | +-----+-------+------+ | 1 | zs | 18 | +-----+-------+------+ #在HBase中查看对应的数据,hbase中将非String类型的value数据全部转为了16进制 hbase(main):013:0> scan 'TEST' ``` 当前节点配置 HBase 环境变量 ``` create table mytable ("id" varchar primary key ,"cf1"."name" varchar,"cf1"."age" varchar) column_encoded_bytes=0; upsert into mytable values ('1','zs','18'); ``` ### **2、**配置 $HBASE_HOME/conf/hbase-env.sh**** #配置 HBase JDK ****export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/**** #配置 HBase 不使用自带的 zookeeper ****export HBASE_MANAGES_ZK=false**** ### **3、配置 $HBASE_HOME/conf/hbase-site.xml** ``` broker.id=0 #注意:这里要唯一的Integer类型 port=9092 #kafka写入数据的端口 log.dirs=/kafka-logs #真实数据存储的位置 zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群 ``` ### **4、配置 $HBASE_HOME/conf/regionservers,配置 RegionServer 节点** ****node3**** ****node4**** ****node5**** ### **5、配置 backup-masters 文件** 手动创建 $HBASE_HOME/conf/backup-masters 文件,指定备用的 HMaster, 需要手动创建文件,这里写入 node5, 在 HBase 任意节点都可以启动 HMaster,都可以成为备用 Master , 可以使用命令:hbase-daemon.sh start master 启动。 ``` [root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node2:/software/ [root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node3:/software/ ``` ### **6、复制 hdfs-site.xml 到 $HBASE_HOME/conf / 下** ``` [root@node1 kafka_2.11-0.11.0.3]# ./startKafka.sh [root@node2 kafka_2.11-0.11.0.3]# ./startKafka.sh [root@node3 kafka_2.11-0.11.0.3]# ./startKafka.sh ``` ### **7、将 HBase 安装包发送到 node3,node5 节点上,并在 node3,node5 节点上配置 HBase 环境变量** ``` #创建topic ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic testtopic --partitions 3 --replication-factor 3 #console控制台向topic 中生产数据 ./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic testtopic #console控制台消费topic中的数据 ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic ``` ### **8、重启 Zookeeper、重启 HDFS 及启动 HBase 集群** ``` [root@node4 ~]# cd /software/ [root@node4 software]# tar -zxvf ./redis-2.8.18.tar.gz ``` 访问 WebUI,http://node4:16010。 停止集群:在任意一台节点上 stop-hbase.sh  ### **9、测试 HBase 集群** 在 Hbase 中创建表 test,指定'cf1','cf2'两个列族,并向表 test 中插入几条数据: ``` #创建安装目录 [root@node4 ~]# mkdir -p /software/redis #进入redis编译目录,安装redis [root@node4 ~]# cd /software/redis-2.8.18 [root@node4 redis-2.8.18]# make PREFIX=/software/redis install ``` **六、搭建 Phoenix** ---------------- 这里搭建 Phoenix 版本为 5.0.0,Phoenix 采用单机安装方式即可,这里将 Phoenix 安装到 node4 节点上。 <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Phoenix 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td><p>Phoenix Client</p></td></tr></tbody></table> **Phoenix 下载及安装步骤如下:** ### **1、下载 Phoenix** Phoenix 对应的 HBase 有版本之分,可以从官网:http://phoenix.apache.org/download.html 来下载,要对应自己安装的 HBase 版本下载。我们这里安装的 HBase 版本为 2.2.6,这里下载 Phoenix5.0.0 版本。下载地址如下: http://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/ 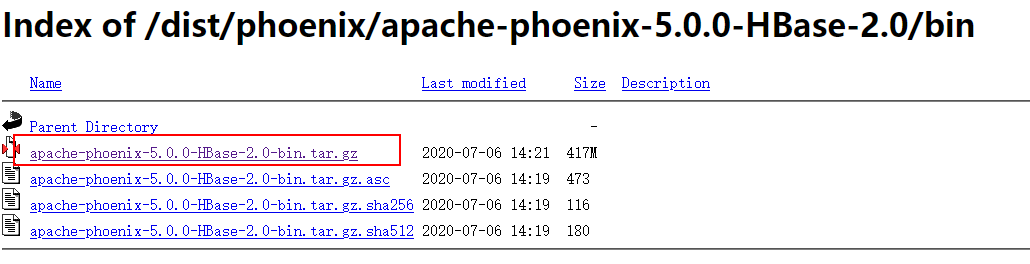 注意:不要下载 phoenix5.1.2 版本,与 Hbase2.2.6 不兼容 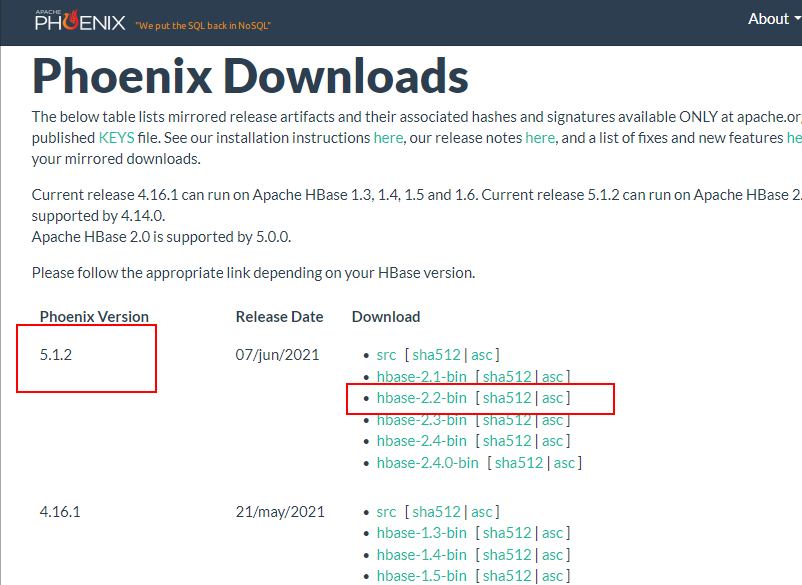 ### **2、上传解压** ``` #将redis-server链接到/usr/local/bin/目录下,后期加入系统服务时避免报错 [root@node4 ~]# ln -sf /software/redis-2.8.18/src/redis-server /usr/local/bin/ #执行如下命令,配置redis Server,一直回车即可 [root@node4 ~]# cd /software/redis-2.8.18/utils/ [root@node4 utils]# ./install_server.sh #执行完以上安装,在/etc/init.d下会修改redis_6379名称并加入系统服务 [root@node4 utils]# cd /etc/init.d/ [root@node4 init.d]# mv redis_6379 redisd [root@node4 init.d]# chkconfig --add redisd #检查加入系统状态,3,4,5为开,就是开机自动启动 [root@node4 init.d]# chkconfig --list ``` ### **3、拷贝 Phoenix 整合 HBase 需要的 jar 包** 将前面解压好安装包下的 phoenix 开头的包发送到每个 HBase 节点下的 lib 目录下。 ``` # 在node4节点上编辑profile文件,vim /etc/profile export REDIS_HOME=/software/redis export PATH=$PATH:$REDIS_HOME/bin #使环境变量生效 source /etc/profile ``` ### **4、复制 core-site.xml、hdfs-site.xml、hbase-site.xml 到 Phoenix** 将 HDFS 中的 core-site.xml、hdfs-site.xml、hbase-site.xml 复制到 Phoenix bin 目录下。 ``` #启动redis [root@node4 init.d]# service redisd start #停止redis [root@node4 init.d]# redis-cli shutdown ``` ### **5、启动 HDFS,Hbase 集群,启动 Phoenix** ``` #进入redis客户端 [root@node4 ~]# redis-cli #切换1号库,并插入key 127.0.0.1:6379> select 1 127.0.0.1:6379[1]> hset rediskey zhagnsan 100 #查看所有key并获取key值 127.0.0.1:6379[1]> keys * 127.0.0.1:6379[1]> hgetall rediskey #删除指定key 127.0.0.1:6379[1]> del 'rediskey' ``` ### **6、测试 Phoenix** ``` #进入flink-conf.yaml目录 [root@node1 conf]# cd /software/flink-1.11.6/conf/ #vim编辑flink-conf.yaml文件,配置修改内容如下 jobmanager.rpc.address: node1 taskmanager.numberOfTaskSlots: 3 ```  注意:在 Phoenix 中创建的表,插入数据时,在 HBase 中查看发现对应的数据都进行了 16 进制编码,这里默认 Phoenix 中对数据进行的编码,我们****在 Phoenix 中建表时可以指定 “column_encoded_bytes=0” 参数,不让 Phoenix 对 column family 进行编码****。例如以下建表语句,在 Phoenix 中插入数据后,在 HBase 中可以查看到正常格式数据: ``` [root@node1 software]# scp -r ./flink-1.11.6 node2:/software/ [root@node1 software]# scp -r ./flink-1.11.6 node3:/software/ #注意,这里发送到node4,node4只是客户端 [root@node1 software]# scp -r ./flink-1.11.6 node4:/software/ ``` 以上再次在 HBase 中查看,显示数据正常  **七、搭建 Kafka** -------------- 这里选择 Kafka 版本为 0.11.0.3, 对应的搭建节点如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Kafka 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td><p>kafka broker</p></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td><p>kafka broker</p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td><p>kafka broker</p></td></tr></tbody></table> **搭建详细步骤如下:** ### **1、**上传解压**** ``` #在node1节点中,启动Flink集群 [root@node1 ~]# cd /software/flink-1.11.6/bin/ [root@node1 bin]# ./start-cluster.sh ``` ### **2、配置 Kafka** 在 node3 节点上配置 Kafka,进入 / software/kafka_2.11-0.11.0.3/config / 中修改 server.properties,修改内容如下: ``` #修改 /etc/profile文件,在最后追加写入如下内容,配置环境变量: [root@node5 software]# vim /etc/profile export FLUME_HOME=/software/apache-flume-1.9.0-bin export PATH=$FLUME_HOME/bin:$PATH #保存以上配置文件并使用source命令使配置文件生效 [root@node5 software]# source /etc/profile ``` ### **3、将以上配置发送到 node2,node3 节点上** ``` [root@node2 ~]# mysql -u root -p123456 mysql> show variables like 'log_%'; ``` ### **4、修改 node2,node3 节点上的 server.properties 文件** node2、node3 节点修改 $KAFKA_HOME/config/server.properties 文件中的 broker.id,node2 中修改为 1,node3 节点修改为 2。 ### **5、创建 Kafka 启动脚本** 在 node1,node2,node3 节点 / software/kafka_2.11-0.11.0.3 路径中编写 Kafka 启动脚本 “startKafka.sh”,内容如下: ``` [root@node2 ~]# service mysqld restart [root@node2 ~]# mysql -u root -p123456 mysql> show variables like 'log_%'; ``` node1,node2,node3 节点配置完成后修改 “startKafka.sh” 脚本执行权限: ``` [root@node3 ~]# cd /software/ [root@node3 software]# tar -zxvf ./maxwell-1.28.2.tar.gz ``` ### **6、启动 Kafka 集群** 在 node1,node2,node3 三台节点上分别执行 / software/kafka/startKafka.sh 脚本,启动 Kafka: ``` mysql> CREATE database maxwell; mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell'; mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%'; mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%'; mysql> flush privileges; ``` ### **7、Kafka 命令测试** ``` producer=kafka kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092 kafka_topic=test-topic #设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column] producer_partition_by=table #mysql 节点 host=node2 #连接mysql用户名和密码 user=maxwell password=maxwell #指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用 client_id=maxwell_first ``` **八、搭建 Redis** -------------- 这里选择 Redis 版本为 2.8.18 版本,Redis 安装在 node4 节点上,节点分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Redis 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td><p>client</p></td></tr></tbody></table> **具体搭建步骤如下:** ### **1、将 redis 安装包上传到 node4 节点,并解压** ``` [root@node2 bin]# cd /software/kafka_2.11-0.11/ [root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test-topic ``` ### **2、node4 安装需要的 C 插件** ``` [root@node3 ~]# cd /software/maxwell-1.28.2/bin [root@node3 bin]# maxwell --config ../config.properties. ``` ### **3、编译 Redis** 进入 / software/redis-2.8.18 目录中,编译 redis。 ### **4、创建安装目录安装 Redis** ``` #startMaxwell.sh 脚本内容: /software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 & ``` 注意:现在就可以使用 redis 了,进入 / software/redis/bin 下,就可以执行 redis 命令。 ### **5、将 Redis 加入环境变量,加入系统服务,设置开机启动** ``` mysql> create database testdb; mysql> use testdb; mysql> create table person(id int,name varchar(255),age int); mysql> insert into person values (1,'zs',18); mysql> insert into person values (2,'ls',19); mysql> insert into person values (3,'ww',20); ```  ### **6、配置 Redis 环境变量** ``` #启动Maxwell [root@node3 ~]# cd /software/maxwell-1.28.2/bin [root@node3 bin]# maxwell --config ../config.properties #启动maxwell-bootstrap全量同步数据 [root@node3 ~]# cd /software/maxwell-1.28.2/bin [root@node3 bin]# ./maxwell-bootstrap --database testdb --table person --host node2 --user maxwell --password maxwell --client_id maxwell_first --where "id>0" ``` ### **7、启动 | 停止 Redis 服务** 后期每次开机启动都会自动启动 Redis,也可以使用以下命令手动启动 | 停止 redis ``` rpm -ivh ./clickhosue-common-static-21.9.4.35-2.x86_64.rpm #注意在安装以下rpm包时,让输入密码,可以直接回车跳过 rpm -ivh ./clickhouse-server-21.9.4.35-2.noarch.rpm rpm -ivh ./clickhouse-client-21.9.4.35-2.noarch.rpm ``` ### **8、测试 redis** ``` <listen_host>::1</listen_host> #注意每台节点监听的host名称配置当前节点host,需要强制保存wq! <listen_host>node1</listen_host> ``` **九、搭建 Flink** ---------------------------- 这里选择 Flink 的版本为 1.11.6,原因是 1.11.6 与 Iceberg 的整合比较稳定。 Flink 搭建节点分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Flink 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td><p>JobManager,TaskManager</p></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td><p>TaskManager</p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td><p>TaskManager</p></td></tr><tr><td><p>192.168.179.7</p></td><td><p>node4</p></td><td><p>client</p></td></tr></tbody></table> **具体搭建步骤如下:** ### ****1、上传压缩包解压**** 将 Flink 的安装包上传到 node1 节点 / software 下并解压: ``` <yandex> <remote_servers> <clickhouse_cluster_3shards_1replicas> <shard> <internal_replication>true</internal_replication> <replica> <host>node1</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node3</host> <port>9000</port> </replica> </shard> </clickhouse_cluster_3shards_1replicas> </remote_servers> <zookeeper> <node index="1"> <host>node3</host> <port>2181</port> </node> <node index="2"> <host>node4</host> <port>2181</port> </node> <node index="3"> <host>node5</host> <port>2181</port> </node> </zookeeper> <macros> <shard>01</shard> <replica>node1</replica> </macros> <networks> <ip>::/0</ip> </networks> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex> ``` ### **2、修改配置文件** 在 node1 节点上进入到 Flink conf 目录下,配置 flink-conf.yaml 文件,内容如下: ``` #node2节点修改metrika.xml中的宏变量如下: <macros> <shard>02</replica> <replica>node2</replica> </macros> #node3节点修改metrika.xml中的宏变量如下: <macros> <shard>03</replica> <replica>node3</replica> </macros> ``` 其中:taskmanager.numberOfTaskSlot 参数默认值为 1,修改成 3。表示数每一个 TaskManager 上有 3 个 Slot。 ### **3、配置 TaskManager 节点** 在 node1 节点上配置 $FLINK_HOME/conf/workers 文件,内容如下: node1 node2 node3 ### **4、分发安装包到 node2,node3,node4 节点** ``` #每台节点启动Clickchouse服务 service clickhouse-server start #每台节点查看clickhouse服务状态 service clickhouse-server status #每台节点重启clickhouse服务 service clickhouse-server restart #每台节点关闭Clikchouse服务 service clickhouse-server stop ``` ### **5、启动 Flink 集群** ``` #选择三台clickhouse任意一台节点,进入客户端 clickhouse-client #查询集群信息,看到下图所示即代表集群配置成功。 node1 :) select * from system.clusters; ``` ### **6、访问 flink Webui** http://node1:8081, 进入页面如下: 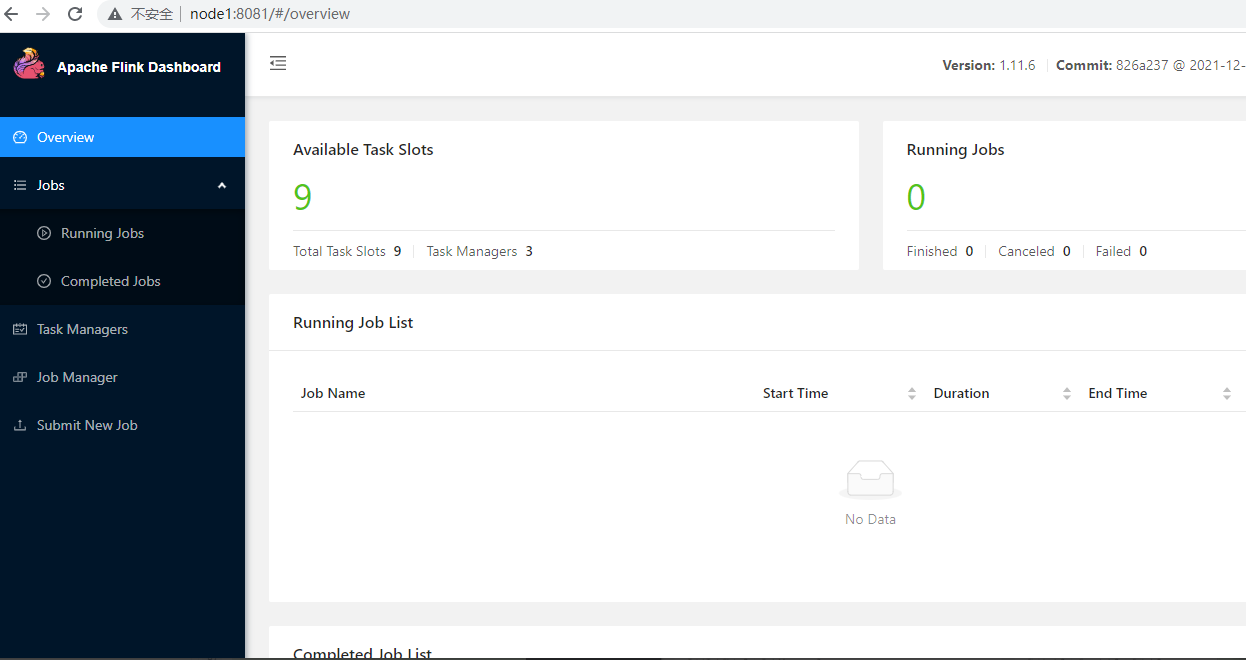 ### **7、准备 “flink-shaded-hadoop-2-uber-2.8.3-10.0.jar” 包** 在基于 Yarn 提交 Flink 任务时需要将 Hadoop 依赖包 “flink-shaded-hadoop-2-uber-2.8.3-10.0.jar” 放入 flink 各个节点的 lib 目录中(包括客户端)。 **十、搭建 Flume** ---------------------------- 这里搭建 Flume 的版本为 1.9.0 版本,Flume 搭建使用单机模式,节点分配如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Flume 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.8</p></td><td><p>node5</p></td><td><p>flume</p></td></tr></tbody></table> **Flume 的搭建配置步骤如下:** ### **1、首先将 Flume 上传到 Mynode5 节点 / software / 路径下, 并解压,命令如下:** ``` #在clickhouse node1节点创建mergeTree表 mt create table mt(id UInt8,name String,age UInt8) engine = MergeTree() order by (id); #向表 mt 中插入数据 insert into table mt values(1,'zs',18),(2,'ls',19),(3,'ww',20); #查询表mt中的数据 select * from mt; ``` ### **2、其次配置 Flume 的环境变量,配置命令如下:** ``` export FLUME_HOME=/software/apache-flume-1.9.0-bin export PATH=$FLUME_HOME/bin:$PATH ``` 经过以上两个步骤,Flume 的搭建已经完成,至此,Flume 的搭建完成,我们可以使用 Flume 进行数据采集。 **十一、搭建 maxwell** ------------------------------- 这里搭建 **Maxwell** 的版本为 1.28.2 版本,节点分配如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>Maxwell</strong></strong></p><p><strong><strong>服务</strong></strong></p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>Node3</p></td><td><p>maxwell</p></td></tr></tbody></table> ### **1、开启 MySQL binlog 日志** 此项目主要使用 Maxwell 来监控业务库 MySQL 中的数据到 Kafka,Maxwell 原理是通过同步 MySQL binlog 日志数据达到同步 MySQL 数据的目的。Maxwell 不支持高可用搭建,但是支持断点还原,可以在执行失败时重新启动继续上次位置读取数据,此外安装 Maxwell 前需要开启 MySQL binlog 日志,步骤如下: **1.1、登录 mysql 查看 MySQL 是否开启 binlog 日志** ``` mysql> show variables like 'log_%'; ``` 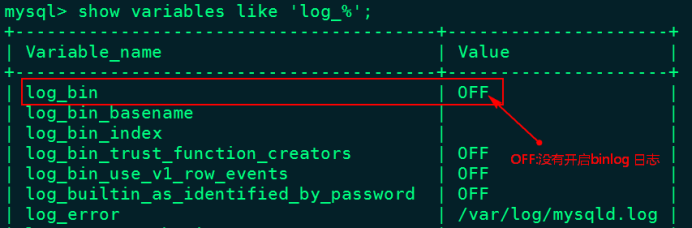 **1.2、 开启 MySQL binlog 日志** 在 / etc/my.cnf 文件中 [mysqld] 下写入以下内容: [mysqld] # 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定义 server-id=123 #配置 binlog 日志目录,配置后会自动开启 binlog 日志,并写入该目录 log-bin=/var/lib/mysql/mysql-bin # 选择 ROW 模式 binlog-format=ROW **1.3、重启 mysql 服务,重新查看 binlog 日志情况** ``` mysql> show variables like 'log_%'; ``` 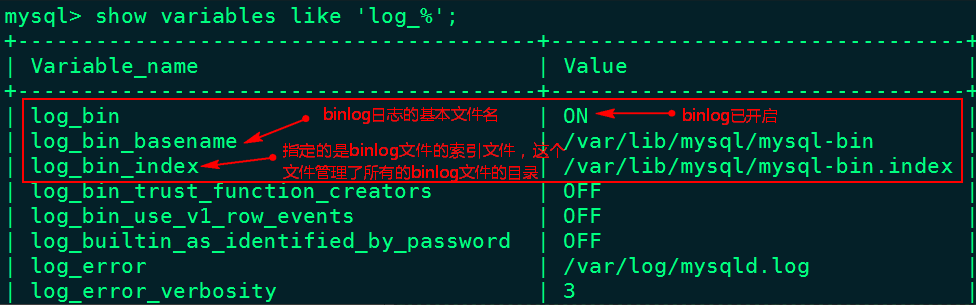 ### **2、安装 Maxwell** 这里 maxwell 安装版本选择 1.28.2, 选择 node3 节点安装,安装 maxwell 步骤如下: **2.1、将下载好的安装包上传到 node3 并解压** **2.2、在 MySQL 中创建 Maxwell 的用户及赋权** Maxwell 同步 mysql 数据到 Kafka 中需要将读取的 binlog 位置文件及位置信息等数据存入 MySQL,所以这里创建 maxwell 数据库,及给 maxwell 用户赋权访问其他所有数据库。 ``` mysql> CREATE database maxwell; mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell'; mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%'; mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%'; ``` **2.3、修改配置 “config.properties” 文件** node3 节点进入 “/software/maxwell-1.28.2”,修改“config.properties.example” 为“config.properties”并配置: ``` kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092 #设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column] producer_partition_by=table #指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用 ``` 注意:以上参数也可以在后期启动 maxwell 时指定参数方式来设置。 **2.4、启动 zookeeper 及 Kafka, 创建对应 test-topic** ``` [root@node1 bin] ``` **2.5、在 Kafka 中监控 test-topic** **2.6、启动 Maxwell** 注意以上启动也可以编写脚本: ``` /software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 & ``` 修改执行权限: ``` chmod +x ./start_maxwell.sh ``` 注意:这里我们可以通过 Maxwell 将 MySQL 业务库中所有 binlog 变化数据监控到 Kafka test-topic 中,在此项目中我们将 MySQL binlog 数据监控到 Kafka 中然后通过 Flink 读取对应 topic 数据进行处理。 **2.7、在 mysql 中创建库 testdb, 并创建表 person 插入数据** ``` mysql> create database testdb; mysql> create table person(id int,name varchar(255),age int); mysql> insert into person values (1,'zs',18); mysql> insert into person values (2,'ls',19); mysql> insert into person values (3,'ww',20); ``` 可以看到在监控的 kafka test-topic 中有对应的数据被同步到 topic 中:  **2.8、全量同步 mysql 数据到 kafka** 这里以 MySQL 表 testdb.person 为例将全量数据导入到 Kafka 中,可以通过配置 Maxwell,使用 Maxwell bootstrap 功能全量将已经存在 MySQL testdb.person 表中的数据导入到 Kafka, 操作步骤如下: 执行之后可以看到对应的 Kafka test-topic 中将表 testdb.person 中的数据全部导入一遍 **十二、搭建 clickhouse** --------------------------- 这里 [clickhouse](https://so.csdn.net/so/search?q=clickhouse&spm=1001.2101.3001.7020) 的版本选择 21.9.4.35,clickhouse 选择分布式安装,clickhouse 节点分布如下: <table><tbody><tr><td><p><strong><strong>节点 IP</strong></strong></p></td><td><p><strong><strong>节点名称</strong></strong></p></td><td><p><strong><strong>clickhouse 服务</strong></strong></p></td></tr><tr><td><p>192.168.179.4</p></td><td><p>node1</p></td><td><p>clickhouse</p></td></tr><tr><td><p>192.168.179.5</p></td><td><p>node2</p></td><td><p>clickhouse</p></td></tr><tr><td><p>192.168.179.6</p></td><td><p>node3</p></td><td><p>clickhouse</p></td></tr></tbody></table> **clickhouse 详细安装步骤如下:** ### ****1、选择三台 clickhouse 节点,在每台节点上安装 clickhouse 需要的安装包**** 这里选择 node1、node2,node3 三台节点,上传安装包,分别在每台节点上执行如下命令安装 clickhouse: ``` rpm -ivh ./clickhosue-common-static-21.9.4.35-2.x86_64.rpm rpm -ivh ./clickhouse-server-21.9.4.35-2.noarch.rpm rpm -ivh ./clickhouse-client-21.9.4.35-2.noarch.rpm ``` ### **2、安装 zookeeper 集群并启动** 搭建 clickhouse 集群时,需要使用 Zookeeper 去实现集群副本之间的同步,所以这里需要 zookeeper 集群,zookeeper 集群安装后可忽略此步骤。 ### **3、配置外网可访问** 在每台 clickhouse 节点中配置 / etc/clickhouse-server/config.xml 文件第 164 行 <listen_host>,把以下对应配置注释去掉,如下: ``` <listen_host>::1</listen_host> #注意每台节点监听的host名称配置当前节点host,需要强制保存wq! <listen_host>node1</listen_host> ``` ### **4、在每台节点创建 metrika.xml 文件,写入以下内容** 在 node1、node2、node3 节点上 / etc/clickhouse-server/config.d 路径下下配置 metrika.xml 文件,默认 clickhouse 会在 / etc 路径下查找 metrika.xml 文件,但是必须要求 metrika.xml 上级目录拥有者权限为 clickhouse ,所以这里我们将 metrika.xml 创建在 / etc/clickhouse-server/config.d 路径下,config.d 目录的拥有者权限为 clickhouse。 在 metrika.xml 中我们配置后期使用的 clickhouse 集群中创建分布式表时使用 3 个分片,每个分片有 1 个副本,配置如下: ``` vim /etc/clickhouse-server/config.d/metrika.xml ``` ``` <clickhouse_cluster_3shards_1replicas> <internal_replication>true</internal_replication> <internal_replication>true</internal_replication> <internal_replication>true</internal_replication> </clickhouse_cluster_3shards_1replicas> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> </clickhouse_compression> ``` 对以上配置文件中配置项的解释如下: * remote_servers: clickhouse 集群配置标签,固定写法。****注意:这里与之前版本不同,之前要求必须以 clickhouse 开头,新版本不再需要。**** * clickhouse_cluster_3shards_1replicas: 配置 clickhouse 的集群名称,可自由定义名称,注意集群名称中不能包含点号。这里代表集群中有 3 个分片,每个分片有 1 个副本。 分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。 副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。 * shard: 分片,一个 clickhouse 集群可以分多个分片,每个分片可以存储数据,这里****分片可以理解为 clickhouse 机器中的每个节点,1 个分片只能对应 1 服务节点****。这里可以配置一个或者任意多个分片,在每个分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。 * replica: 每个分片的副本,默认每个分片配置了一个副本。也可以配置多个,副本的数量上限是由 clickhouse 节点的数量决定的。如果配置了副本,读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进行连接。该机制利于系统的可用性。 * internal_replication: 默认为 false, 写数据操作会将数据写入所有的副本,设置为 true, 写操作只会选择一个正常的副本写入数据,数据的同步在后台自动进行。 * zookeeper: 配置的 zookeeper 集群,****注意:与之前版本不同,之前版本是 “zookeeper-servers”。**** * macros: 区分每台 clickhouse 节点的宏配置,macros 中标签 <shard> 代表当前节点的分片号,标签 < replica > 代表当前节点的副本号,这两个名称可以随意取,后期在创建副本表时可以动态读取这两个宏变量。注意:每台 clickhouse 节点需要配置不同名称。 * networks: 这里配置 ip 为 “::/0” 代表任意 IP 可以访问,包含 IPv4 和 IPv6。 注意:允许外网访问还需配置 / etc/clickhouse-server/config.xml 参照第三步骤。 * clickhouse_compression: MergeTree 引擎表的数据压缩设置,min_part_size:代表数据部分最小大小。min_part_size_ratio:数据部分大小与表大小的比率。method:数据压缩格式。 ****注意:需要在每台 clickhouse 节点上配置 metrika.xml 文件,并且修改每个节点的 macros 配置名称。**** ``` #node2节点修改metrika.xml中的宏变量如下: #node3节点修改metrika.xml中的宏变量如下: ``` ### **5、在每台节点上启动 / 查看 / 重启 / 停止 clickhouse 服务** 首先启动 zookeeper 集群,然后分别在 node1、node2、node3 节点上启动 clickhouse 服务,这里每台节点和单节点启动一样。启动之后,clickhouse 集群配置完成。 ``` service clickhouse-server start service clickhouse-server status service clickhouse-server restart service clickhouse-server stop ``` ### **6、检查集群配置是否完成** 在 node1、node2、node3 任意一台节点进入 clickhouse 客户端,查询集群配置: ``` node1 :) select * from system.clusters; ```  查询集群信息,也可以使用如下命令 ``` node1 :) select cluster,host_name from system.clusters; ``` 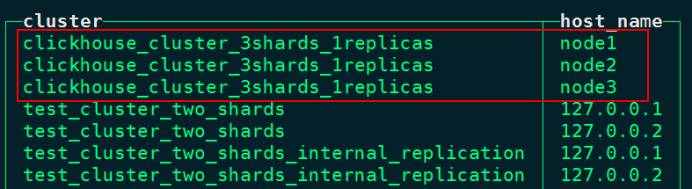 ### **7、测试 clickhouse** ``` create table mt(id UInt8,name String,age UInt8) engine = MergeTree() order by (id); insert into table mt values(1,'zs',18),(2,'ls',19),(3,'ww',20); ``` * 📢博客主页:[https://lansonli.blog.csdn.net](https://lansonli.blog.csdn.net/ "https://lansonli.blog.csdn.net") * 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! * 📢本文由 Lansonli 原创,首发于 CSDN 博客🙉 * 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
yg9538
2022年7月28日 22:46
1111
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期